
Estimation of above-ground carbon storage in the Jiufengshan National Forest Park of Wuhan based on GF-2 images
-
摘要:
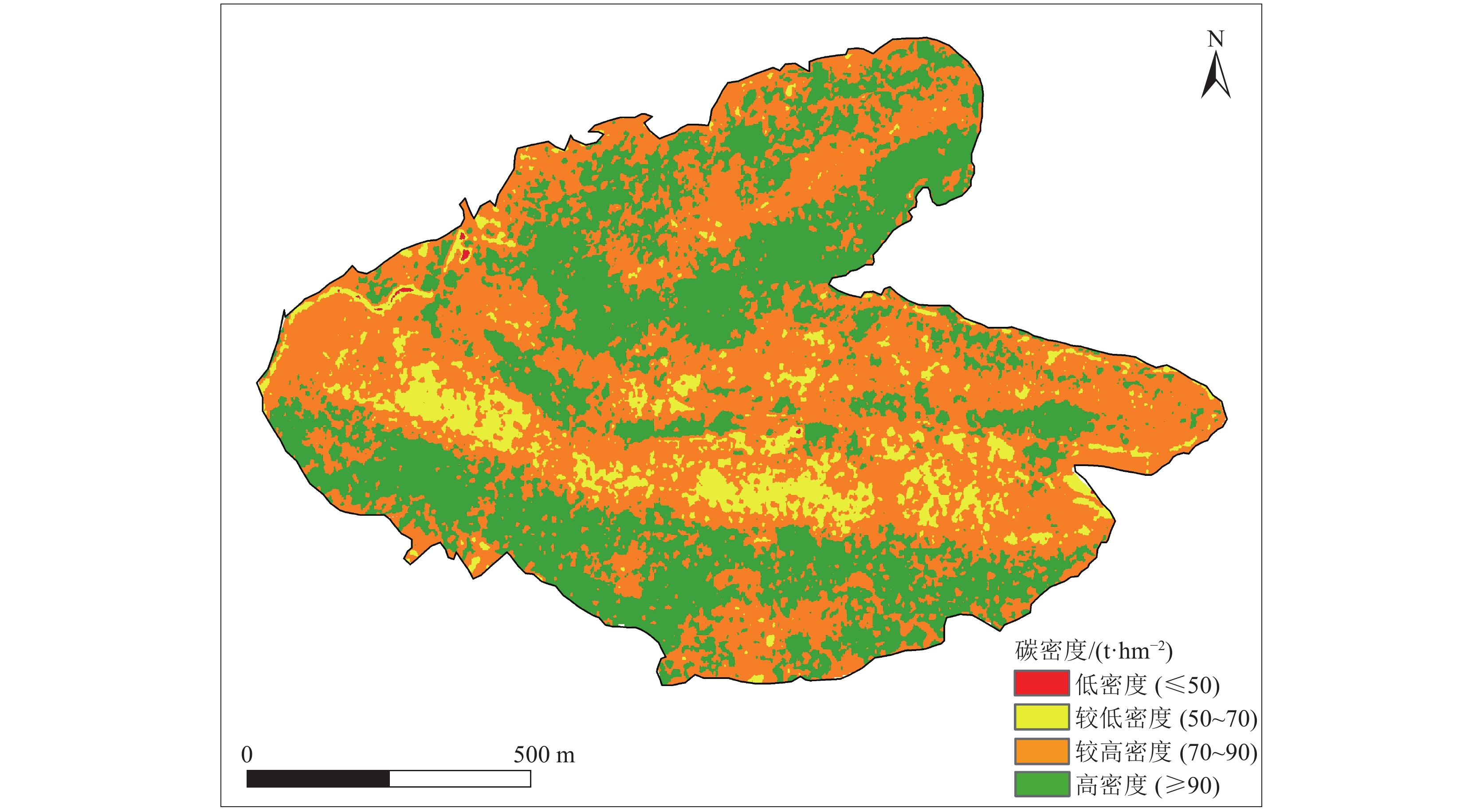
探究国产高分辨率数据在森林碳储量估算研究中的潜力,为构建森林碳储量估算模型提供新思路。选取武汉市九峰山国家森林公园为研究对象,以GF-2遥感影像为数据源,结合地面实测信息,对研究区森林地上碳储量进行估算,共提取6个植被指数、4个波段值、8种纹理特征,筛选出9个与实测碳储量相关的遥感变量,运用线性与非线性方程对单个高相关变量和多个相关变量进行建模,选出最优模型,为进一步提高预测精度,将模型代入4种纹理窗口(3×3、5×5、7×7、9×9)。结果表明:通过遥感图像提取的植被指数之间,具有较强的共线性,单变量建立的模型精度低于多变量模型;利用均方根误差RMSE与决定系数R²对4个窗口下模型的预测精度进行评价,模型在5×5窗口下预测效果最好(R² = 0.73,RMSE = 0.5),3×3窗口下预测效果最差(R² = 0.64,RMSE = 0.8),将所有估测模型进行比较,在纹理窗口下模型精度提高了0.11。利用5×5窗口下构建的多变量模型对研究区碳储量进行估算,九峰山国家森林公园碳储总量为1.06×104 t ,总体平均碳密度为84.59 t/hm2,具有一定的固碳作用。选用国产高分辨率影像GF-2数据对武汉市九峰山森林公园进行反演研究,能很好地运用在森林植被碳储量定量与生长状况领域。研究结果对“双碳”目标下森林生态系统碳汇监测与管理具有重要科学意义。
Abstract:Exploring the potential of domestic high-resolution data in the estimation of forest carbon storage estimation research provides a new approach for the construction of forest carbon storage estimation model. In this study, the Jiufengshan National Forest Park in Wuhan City was selected, GF-2 remote sensing image was used as the data source, and ground measured information was combined to estimate forest AGC storage in the Park. A total of 6 vegetation indices, 4 band values and 8 texture features were extracted, and 9 remote sensing variables that related to measured carbon storage were screened out. Linear and nonlinear equations were used to model a single highly correlated variable and multiple correlated variables, and subsequently the optimal model was therefore selected. In order to further improve the prediction accuracy, the model was carried into four texture Windows (3×3, 5×5, 7×7, 9×9). The results showed that the vegetation index extracted from remote sensing images had strong collinearity, and the accuracy of the single variable model was lower than that of the multiple regression model. The root-mean-square (RMSE) and the coefficient of determination R² were used to evaluate the prediction accuracy of the model under four Windows. We showed that the model had the best prediction power under the 5×5 window (R²=0.73, RMSE=0.5), and the prediction power was the lowest under the 3×3 window (R²=0.64, RMSE=0.8), compared with all the estimated models, the accuracy of the model is improved by 0.11 in the texture window. Therefore, the constructed multivariate model was used to estimate carbon storage with a 5×5 window. The total carbon storage in the Jiufengshan National Forest Park was 1.06×104 t, the overall average carbon density was 84.59 t/hm2, it has a certain carbon fixation effect. Using domestically produced high-resolution image of GF-2 satellite imagery data to invert Jiufengshan Forest Park in Wuhan, it can be well used in the field of quantitative carbon storage and growth status of forest vegetation. The research has important scientific significance for the monitoring and management of forest carbon sink under the “carbon peaking and carbon neutrality” target.
-
Keywords:
- GF-2 /
- above-ground carbon storage /
- remote sensing inversion /
- forest carbon sink /
- Hubei Province
-
矿物识别是采矿工程、地质学等相关学科研究的基础。国内目前主要的矿物识别方法是依据人工经验,通常是依据其颜色、硬度和透明度,同时结合结晶习性、解理、断口等物理特征判断矿物种类(赵明,2010)。这对于从事矿物识别及相关工作人员的专业知识与经验要求较高,而且对矿石识别的准确度较低,难以大规模应用于实际场景。近年来,为了提高矿石识别效率及解决识别准确度低的问题,以机器学习为代表的矿物智能识别成为了研究的热点(周永章等,2018;郭艳军等,2020;郝慧珍等,2021)。
常规的矿物识别方法主要是依据矿物的属性,如外表形态、物理性质、化学成分等属性特征及相应的组合,使用能量散射光谱(EDS)(El Haddad et al., 2019)、电子探针(Tsuji et al., 2010)、激光诱导击穿光谱(LIBS)(Khajehzadeh et al., 2016)、显微光学观察(Maitre et al., 2019)、光谱分析(张旭等,2020)等方法实现矿物与岩石的识别。这些方法虽然准确率较高,但是需要用到专业仪器,过程复杂,整体效率偏低。
近年来,深度学习在矿物识别领域取得了良好效果(Trejbal et al., 2020;许振浩等,2021;周永章等,2021)。Baykan et al.(2010)利用多层感知机(MLP,Multilayer Perceptron)识别石英、白云母、黑云母等矿物。Izadi et al.(2013)利用两层神经网络,成功识别14种矿物。徐述腾等(2018)设计了Unet模型,建立对矿石矿物镜下照片的智能识别。Liu et al. (2019)基于深度学习和迁移学习算法,以12种岩石矿物为研究对象,建立了岩石矿物识别模型。彭伟航等(2019)基于改进InceptionV3模型对常见的16类矿物进行图像识别,准确率达到86%。李明超等(2020)基于迁移学习的方法与深度学习模型,根据19类矿物的颜色与纹理特征,建立了矿物图像识别耦合模型,并搭建矿物识别应用系统。刘艳鹏等(2020)利用卷积神经网络进行成矿预测。王李管等(2020)利用预训练的卷积神经网络对黑钨矿图像进行迁移学习实验,对黑钨原矿石的识别准确率达到99.6%。Liu et al.(2021)结合模型深度、模型结构和数据集大小,建立了小型矿石图像分类的深度学习模型。Zhou et al.(2022)在MobileNet网络的基础上,利用迁移学习与SENet机制相结合的方式,使矿石分类的准确率达到96%。通过上述文献不难看出,基于深度学习的矿物识别可以较好地解决传统方法中效率偏低的问题,并且准确率有所提高,但仍存在矿物识别种类较少,同时矿物形态特征发生变化时,已有的深度学习模型难以准确提取特征,以致于泛化能力不强的问题。
针对现有问题,本文以26类矿物的矿石图像作为研究对象,提出了一种基于改进的ConvNeXt网络的矿物智能识别模型,通过利用迁移学习策略,引入超强通道注意力机制,在加强矿物特征提取的同时,进一步提高特征之间的融合,以及矿物识别准确率与模型的泛化性,从而实现对不同矿物的高效准确识别。
1. 基本概念
在计算机视觉中,卷积神经网络凭借其对图像特征的快速提取与识别物体准确率高一直占据着重要地位。ConvNeXt网络是2022年由Facebook团队提出的纯卷积神经网络架构模型(Liu et al., 2022)。对于ConvNeXt网络,根据模型计算复杂度的不同,共有4个(T/S/B/L)版本。本文综合考虑矿物的类别与数据集的大小,选取了ConvNeXt-T版本。在ConvNeXt-T网络中,主要是由ConvNeXt块构成。对于ConvNeXt块,其输入特征图为h×w×dim(高度×宽度×特征图的通道深度),经过深度可分离卷积 (DepthwiseConv2D)及层标准化(Layer Normalization),对多个特征通道进行融合,之后经过普通卷积(Conv2D)等操作,对特征图进行一系列升维与降维处理,使其输出特征图为h×w×dim,具体变化过程如图1所示。对于整个ConvNeXt-T网络结构,首先输入大小为224×224×3(即高度与宽度大小为224,通道数为3)的图像,经过第一次卷积操作后特征图变为56×56×96;其次,经过一系列ConvNeXt块同时结合下采样(Downsample)操作,特征图变为7×7×768,最后,经全局平均池化(Global Avg Pooling)、层标准化与全连接(Linear)等操作后,特征图输出大小为1000。具体结构如表1所示。
表 1 ConvNeXt-T结构Table 1. Structure diagram of ConvNeXt-T层名 输入 ConvNeXt-T 输出 conv1 224×224×3 4×4,96,stride4
Layer Norm56×56×96 conv2_x 56×56×96 [d7×7,961×1,3841×1,96]×3 56×56×96 conv3_x 56×56×96 Downsample [d7×7,1921×1,7681×1,192]×3 28×28×192 conv4_x 28×28×192 Downsample[d7×7,3841×1,15361×1,384]×9 14×14×384 conv5_x 14×14×384 Downsample[d7×7,7681×1,30721×1,768]×3 7×7×768 7×7×768 Global Avg PoolingLayer NormalizationLinear 1000 2. 模型构建
2.1 迁移学习
理论上,深度学习可以提取图像中不同层次的特征,表征物体之间的细微差别。然而,这需要以足够多且高质量的已标注数据集为前提,进而训练得出已建立网络模型中的巨量参数。在实际应用场景中,研究对象(如矿物图像领域)往往没有建立大量带标签的数据集,通常会采用迁移学习的方式来解决(Zamir et al., 2018)。目的主要是实现模型之间的参数共享与相应的特征迁移,提高其泛化能力,同时减少训练成本。
考虑到研究的矿物对象种类及数据集大小,本文通过迁移学习的方式,实现ConvNeXt原模型与矿物识别模型之间参数共享,以降低其训练成本,提高矿物智能识别模型的泛化性。①利用原有的ConvNeXt网络对ImageNet-1k数据集进行预训练,得到ConvNeXt网络预训练模型与对应的模型权重文件;②通过微调的方式,删除上述预训练模型中原有的全连接层,并设计适合矿物研究对象的全连接层,从而适合本文研究的矿物识别领域;③基于迁移学习的方式,将以矿物种类的数量为标准而设计的全连接层与ConvNeXt模型相结合,以共享参数信息与特征权重,从而重新训练模型参数,加快训练速度。
2.2 超强通道注意力模块(ECA-Net)
现有研究表明,将注意力机制添加到已有的卷积神经网络框架或模型中可以提高其性能。比如,SENet通过对特征图中的通道维度进行信息权重分配,在ImageNet数据集上降低了0.4%~1.8%的错误率(Hu et al., 2018);SKNet采用自适应的注意力编码机制,与ResNeXt50相比降低了1.44%的错误率(Li et al., 2019);CBAM提出了通道与空间融合的注意力机制,较ResNet50降低了1.9%的错误率(Woo et al., 2018)。在复杂的环境变化下,矿物的特征发现多样化,本文在ConvNeXt网络基础上,在ConvNeXt块之后加入超强通道注意力机制ECA(Efficient Channel Attention)(Wang et al., 2020),加强了对矿物特征的提取。其主要流程为:首先,输入矿物图像特征图大小为C×H×W;在此基础上,进行GAP(全局平均池化)操作以减少模型参数量;其次,使用一维卷积(大小为k)获取矿物图像特征在每个空间通道的权重,其中,k表示局部通道交互的覆盖率,同时利用Sigmoid进行对应权重的归一化;最后,将已生成的各个通道权重与输入特征图相加权,进而得到矿物图像特征权重。超强通道注意力(ECA)模块如图2所示。
对于整个ECA模块来讲,主要是用Wk来表示学习到的通道注意力,其中,Wk涉及K×C个参数,并且Wk避免了不同通道的完全独立:
[w1,1⋯w1,k00⋯⋯00w2,2⋯w2,k+10⋯⋯0⋮⋮⋮⋮⋱⋮⋮⋮0⋯00⋯wC,C−k+1⋯wC,C] (1) 其中,ECA模块主要的部分是:利用卷积核大小为k的一维卷积实现每个通道之间的信息交互,从而生成每个通道对应的权重:
w=σ(C1Dk(y)) (2) 其中,CID为一维卷积,σ为Sigmoid函数。因此,ECA在保证了模型性能的同时,提高了模型效率(降低了模型复杂度)。
2.3 矿物智能识别模型
针对矿物图像识别困难及准确率较低的缺陷,本文在原有ConvNeXt网络的基础上,利用迁移学习策略与引入ECA模块,构建矿物智能识别网络模型,名称为ECA-ConvNeXt网络模型。具体来讲,主要是利用在ImageNet已经预训练的ConvNeXt模型,经过一定处理后,通过迁移学习加载到矿物识别模型框架内,而在现有ConvNeXt网络的基础上,为了实现矿物图像特征之间的融合,在每一个ConvNeXt块后(即在conv_2,3,4,5后),都添加一个ECA模块,实现了矿物图像局部跨通道交互融合的目的,最后经全局平均池化等操作,实现了对于矿物的识别。最终,本文构建的ECA-ConvNeXt网络模型,以不同种类矿物的矿石图像数据为研究对象,进行一系列实验后,矿物识别准确率及模型性能与现有主流网络相比都有较大提升。矿物智能识别模型整体结构如图3所示。
3. 实验过程
3.1 矿物图像数据采集
本文选取常见的26类矿物作为研究对象,包括斑铜矿、辰砂、赤铁矿、磁黄铁矿、磁铁矿、毒砂、方解石、方铅矿、橄榄石、铬铁矿、黑钨矿、褐铁矿、黄铁矿、黄铜矿、辉钼矿、辉锑矿、辉铜矿、孔雀石、蓝铜矿、铝土矿、软锰矿、闪锌矿、石英、铁钼矿、雄黄、萤石。
由于矿物种类不同,而且同类矿物产地来源也有所不同。不同的矿物经采集、运输等过程,不可避免地会沾染灰尘等,影响矿物图像的清晰度,以致于影响模型的精度。因此,首先对26类矿物的矿石进行水洗、晾晒等操作,将已经处理过的矿物的矿石样本放置于实验平台之上,然后使用佳能单反相机从不同的方向拍摄,拍摄距离约30 cm,其部分矿物的矿石样本图像如图版Ⅰ所示。
3.2 矿物图像数据增强
在深度学习中,是否有充足的数据样本是保证训练模型效果优劣与泛化能力强弱的基础。但是在实际应用中,往往没有建立统一的大型数据集。为了解决因数据集的不足造成识别准确率低等问题,通常采用数据增强的方式提升模型的效果。针对本文中不同矿物矿石图像的特点,对其进行图像裁剪、旋转,图像亮度调整和随机添加噪声操作。对于这些数据增强方法操作后,每类矿物的矿石图像原始数量和增强后的数量如表2所示,按照序列号进行排序,共计34576张图片。
表 2 矿物类别及图像数量统计Table 2. Mineral category and image quantity statistics序列号 矿物类别 原始图像数量/张 增强后的图像数量/张 序列号 矿物类别 原始图像数量/张 增强后的图像数量/张 1 斑铜矿 194 776 14 黄铜矿 360 1440 2 辰砂 214 856 15 辉钼矿 278 2224 3 赤铁矿 258 1032 16 辉锑矿 472 1888 4 磁黄铁矿 146 584 17 辉铜矿 300 1200 5 磁铁矿 286 1144 18 孔雀石 466 1864 6 毒砂 216 864 19 蓝铜矿 310 1240 7 方解石 374 1496 20 铝土矿 298 1192 8 方铅矿 516 2064 21 软锰矿 324 1296 9 橄榄石 142 568 22 闪锌矿 362 1448 10 铬铁矿 246 984 23 石英 257 1285 11 黑钨矿 324 1296 24 铁钼矿 121 968 12 褐铁矿 440 1760 25 雄黄 352 1408 13 黄铁矿 399 1995 26 萤石 426 1704 3.3 实验方法与环境配置
(1)实验设计
在对矿物识别模型实验之前,需将矿物图片按6∶2∶2的比例划分为矿物训练集、矿物验证集与矿物测试集。其中,矿物训练集中的图片用于训练本文构建模型中的未知参数,验证集目的是为了验证模型训练的结果,而其测试集用于检验矿物识别模型的效果。根据本文矿物数据集的大小,设置batch size大小为32,初始学习率为0.001,迭代200次,采用交叉熵函数作为模型的损失函数。
在矿物图片实验过程中使用Adam作为优化器,同时利用余弦退火对矿物图片训练过程中学习率进行不断优化,使其接近全局最优值点,进而得到矿物识别模型。
(2)环境配置
本实验基于Pytorch框架进行矿物识别模型的训练、验证与测试。其中,硬件环境:处理器为英特尔 i9-10900K(64GB),显卡为NVIDIA GeForce RTX 3080。软件环境:CUDA11.4,cuDNN8.2.4,Pytorch1.11,PyCharm2021专业版。
4. 结果分析
4.1 训练结果
本文利用训练准确率与验证准确率评估ECA-ConvNeXt网络矿物识别模型的训练效果。其中,训练准确率与验证准确率相差太大表示模型过拟合,导致网络泛化能力差。
为了验证本文模型的有效性,在一定条件下(数据集与处理方法相同,训练200次),分别在训练集与验证集上与5种典型图像分类网络进行横向的对比,其结果如图4所示。图4−a为训练集上不同模型准确率的对比,而图4−b为验证集上不同模型的准确率对比。在训练集上,6个网络的训练准确率均达到90%以上;在验证集上,VGG19准确率为92.22%,GoogLeNet准确率为92.43%,ResNet50准确率为95.04%,ResNeXt50准确率为95.43%,ConvNeXt准确率为97.53%,本文模型准确率为99.42%。从以上结果可知,本文构建的ECA-ConvNeXt网络模型与其他5种网络相比,取得了较优成绩,总体上性能最佳。
![]() 图 4 训练集(a)与验证集(b)不同网络的准确率对比Figure 4. Comparison of the accuracy of different networks in training sets (a) and validation sets (b)
图 4 训练集(a)与验证集(b)不同网络的准确率对比Figure 4. Comparison of the accuracy of different networks in training sets (a) and validation sets (b)4.2 实验结果
4.2.1 模型性能
混淆矩阵是评判模型优劣的一种指标,常用于评判图像分类模型的优劣。本文基于改进的ConvNeXt矿物智能识别模型对于26类矿物的混淆矩阵如图5所示。其中,大多数准确率达97%及以上,对黄铁矿进行识别分类时只有94%,识别成毒砂与方解石有2%的概率,而识别成黄铜矿与闪锌矿有1%的概率。
对于图像分类任务,如何对图像所属类别进行正确分类是其主要的目的。在实际情况中,预测值与真实值的情况如表3所示。其中,TP为真实值为正,预测值为正;FP为真实值为正,预测值为负;FN为真实值为负,预测值为正;TN为真实值为负,预测值为负。
表 3 分类指标Table 3. Classification index预测值 正例(Positive) 反例(Negative) 真实值 正例(Positive) TP FP 反例(Negative) FN TN 为了验证本文构建的矿物智能识别模型的有效性,选用准确率(Accuracy)、精确率(Precision)与召回率(Recall)指标对6种矿物识别模型进行效果评估。计算公式如下所示:
Accuracy=TP+TNTP+TN+FP+FN (3) Precision=TPTP+FP (4) Recall=TPTP+FN (5) 在相同训练集上进行训练的6种矿物识别模型,在同一测试集上进行对应的测试,结果如表4所示。从表4可以看出,分类准确率与模型的复杂度呈正相关。其中,GoogLeNet优于VGG19,而ResNet50引入残差结构,ResNeXt50则是在ResNet的基础上结合分组卷积的优点,使其效果得到提升,而ConvNeXt是借鉴Swin-Transformer的结构,改进卷积神经网络的结构提升其性能。本文在ConvNeXt的基础上,引入注意力机制,使其准确率、精确率、召回率分别达到98.58%、98.62%、98.73%,与其他网络相比均是最佳。因此,对于ConvNeXt网络的改进较有效。
表 4 各个模型的测试评估结果Table 4. Test evaluation results of each model模型 准确率 精确率 召回率 VGG19 91.25% 91.62% 91.70% GoogLeNet 92.66% 93.36% 92.33% ResNet50 94.88% 95.04% 94.95% ResNeXt50 95.07% 95.45% 95.03% ConvNeXt 96.60% 96.62% 96.73% 本文模型 98.58% 98.62% 98.73% 4.2.2 消融实验分析
为了验证所提出的优化方法对于原ConvNeXt模型性能的影响,在相同实验条件下,采用不同优化方法对ConvNeXt模型进行测试,其结果如表5所示。在原ConvNeXt网络模型的基础上,利用ECA或迁移学习的方法,使其在准确率、精确率与召回率3项指标上都有1%左右的性能提升,而本文提出的改进ConvNeXt模型,只增加了极少的参数量与模型大小,约有2%的性能提升,取得了不错的效果。因此,本文提出的改进ConvNeXt模型更适合于对矿物的智能识别。
表 5 不同优化方法对于ConvNeXt模型的影响Table 5. The impact of different optimization methods on the ConvNeXt model模型 参数量 模型大小 准确率 精确率 召回率 ConvNeXt 27.80M 106.25M 96.60% 96.62% 96.73% ECA
+ConvNeXt27.82M 106.26M 97.62% 97.65% 97.61% 迁移学习+ConvNeXt 27.82M 106.26M 97.87% 97.90% 98.02% 本文模型 27.84M 106.27M 98.58% 98.62% 98.73% 4.3 矿物图像特征图可视化
卷积神经网络主要是通过提取图像中物体或其他本身所具有的特征,达到识别、检测、分割等目的,但对于其所提取的特征是什么,哪些区域对于识别起作用,以及由此得出的最终结果都无从得知。为了确定本文提出的矿物识别模型对于矿石图像中哪些区域识别的影响较大,本文利用Grad-CAM(Selvaraju et al., 2017)获得可视化矿石图像的特征图。主要是将本文提出的网络模型的最后一层feature maps(特征图),利用Grad-CAM进行可视化输出,可以观察矿物图像中的有效区域对于模型识别的影响。
图6是在不同模型的条件下,所提取特征的可视化热力图。其中,图6中从上到下的5种矿物分别是:斑铜矿、赤铁矿、橄榄石、辉钼矿和石英。而图6中从左到右依次是原图与依据VGG19、GoogLeNet、ResNet50、ResNeXt50、ConvNeXt和本文所提出的模型生成与之对应的特征图。其中,通过对于原图与不同模型之间特征图的对比(图中颜色越深,代表模型对于所在区域关注度越高,对识别的结果影响越大),本文提出的矿物识别模型优于传统模型,同时在对矿物识别的过程中,主要以矿物的边缘和颜色为感兴趣区域,也从侧面说明本文模型对于矿物特征的提取效果好,实现了对矿物的准确识别,证明了模型的有效性。因此,本文提出的基于改进的ConvNeXt网络矿物识别模型,提高了对于矿物的特征提取能力,较好地解决了矿物识别效率低的问题。
5. 结 论
在原有ConvNext网络的基础上,利用26类矿物34576张图像,通过迁移学习与引入ECA模块,构建了基于改进的ConvNeXt网络的矿物智能识别模型,实现了对于矿物分类的高效准确识别。得到了以下结论。
(1)通过在ImageNet上已预训练的ConvNeXt模型,经一定处理后利用迁移学习的方法,加载到矿物识别模型框架中,同时针对不同矿物图像自身特点,通过引入超强注意力通道(ECA)机制,构建了ECA-ConvNeXt网络矿物识别模型,提高了矿物图像特征融合的能力与训练速度。
(2)采用ECA-ConvNeXt矿物图像识别模型,将26类矿物图像与VGG19、GoogLeNet、ResNet50、ResNeXt50和ConvNeXt网络相比,其在训练过程收敛更快,同时在准确率、精确度与召回率3项数据上均是最佳,分别达到了98.58%、98.62%与98.73%;而消融实验,进一步证明了模型的有效性。
(3)利用Grad-CAM方法,在矿物原图的基础上,通过与不同模型之间矿物图像特征图的可视化结果对比,进一步证明了本文模型的优越性与在矿物识别领域的显著性。
本文研究成果对于矿物智能识别领域具有一定的借鉴意义,如何进一步提高矿物智能识别的速度与准确率,以及如何将其应用到实际场景等仍然是重要的研究方向。
-
![]()
图 2 回归模型实测值和预测值散点图
Figure 2. A scatter plot of measured and predicted values from regression model
表 1 高分二号卫星简介
Table 1 Brief introduction of GF-2 satellites
卫星 分辨率 波段 波长范围/μm 重访周期/d 地面幅宽/km
高分二号
GF-2全色1 m Band1 0.45~0.90 5 >45
多光谱4 mBand2 0.45~0.52 Band3 0.52~0.59 Band4 0.63~0.69 Band5 0.77~0.89  下载: 导出CSV
下载: 导出CSV
表 2 实测样地信息
Table 2 Measured sample information
林分类型 样本量 主要树种(组) 群落组成 最大树高/m 最小树高/m 平均树高/m 最大胸径/cm 最小胸径/cm 平均胸径/cm 针叶林 7 马尾松
马尾松-杉木马尾松、杉木,麻栎、栓皮栎、青冈、香樟、冬青、枫香、柿树、柯树、檵木 15.2
~
22.22.6
~
4.38.6
~
12.032.6
~
58.55.1
~
6.315.0
~
19.0阔叶林 7 栎树
青冈-枫香
青冈-栎树栓皮栎、麻栎、青冈、小叶栎、马尾松、冬青、油茶树、短柱茶、山矾、朴树、柿树、女贞、枫香、苦槠 14.5
~
23.43.5
~
5.79.0
~
15.030.7
~
54.55
~
6.815.8
~
23.8针阔混交林 4 马尾松-栎树
马尾松-栎树-枫香
马尾松-栎树-青冈
马尾松-杉木-栎树栓皮栎、麻栎、小叶栎、青冈、马尾松、冬青、枫香、杉木、檵木 16.9
~
23.34.1
~
6.610.8
~
12.636.7
~
52.35.1
~
6.314.8
~
21.0
下载: 导出CSV
表 3 优势树种生物量方程
Table 3 The biomass equations of the predominant tree species
树种 回归方程 马尾松 Pinus massoniana W=0.1056×(D2H)0.8247 麻栎 Quercus acutissima W=1.13796×10−3D2.0825H2.1154 青冈 Quercus glauca W=0.018851976×(D2H)1.091681772 樟树 Cinnamomum camphora W=0.112503(D2H) 杉木 Cunninghamia lanceolate W=0.257×(D2H)0.697 阔叶树 Hardwood forest W=−1.982+1.209ln(D2) 注:W表示生物量;D表示胸径;H表示高度
下载: 导出CSV
表 4 植被指数及纹理参数计算方法
Table 4 Vegetation index and texture parameter calculation methods
类型 遥感数据 计算公式 植被指数 归一化植被指数(NDVI) NDVI=NIR−RNIR+R 比值植被指数(RVI) RVI=NIRR 差值植被指数(DVI)
DVI=NIR−R土壤调整植被指数(SAVI) SAVI=(NIR−R)(1+L)(NIR+R)+L 增强型植被指数(EVI) EVI=2.5NIR−RNIR+6R−7.5BLUE+1 大气阻抗植被指数(ARVI) ARVI=NIR−(2R−BLUE)NIR+(2R−BLUE) 纹理特征 均值 ∑N−1i,j=0iPij 方差 ∑N−1i,jPij(i−ME)2 均匀性 ∑N−1i,j=0iPij1+(i−j)2 对比度 ∑N−1i,j=0iPij(i−j)2 异质性 ∑N−1i,j=0iPij|i−j| 熵 ∑N−1i,j=0iPij(−lnPij) 二阶矩 ∑N−1i,j=0iPij2 相关性 ∑N−1i,j=0iPij[(i−ME)(j−ME)√VAiVAj] 注:NIR—近红外波段;R—红波段;BLUE—蓝波段;L—土壤调节因子(L = 0.5);ij—第i行第j列位置上的像元亮度值; {{{{{P}_{ij}}}}}— 归一化共生矩阵;N—计算纹理特征时移动窗口的大小;ME—灰度共生矩阵的均值, V{A}_{i}V{A}_{j} —方差
下载: 导出CSV
表 5 建模因子相关性分析
Table 5 Modeling factor correlation analysis
变量 变量因子 相关系数 X1 NDVI 0.87** X2 RVI 0.86** X3 SAVI 0.80** X4 DVI 0.80** X5 EVI 0.77** X6 B4 0.77** X7 ARVI 0.76* X8 Mean 0.76** X9 Correlation −0.70* 注:**表示p<0.01;*表示p<0.05(双尾);−表示负相关
下载: 导出CSV
表 6 回归模型与参数
Table 6 Regression model and the parameters
回归模型 方程 R2 调整后R2 F Sig 多元逐步回归模型 Y=18.549−46.981X1+3.453X2+X6 0.85 0.80 15.06 0.00 一元线性模型 Y=7.393X1−1.407 0.85 0.71 28.61 0.00 二次曲线模型 Y=46.12−138.207X1+111.255X12 0.83 0.79 21.69 0.00 S模型 Y=e2.598−0.893/X1 0.70 0.73 26.90 0.00 复合模型 Y=0.854×8.341X1 0.75 0.73 29.64 0.00 成长模型 Y=e0.158+2.121X1 0.75 0.73 29.64 0.00 指数模型 Y=0.854e2.121X1 0.75 0.73 29.64 0.00 Logistic模型 Y=1/(0+1.171×(0.12×10−4)X1) 0.75 0.73 29.64 0.00 线性模型 Y=7.393X1−1.407 0.74 0.72 28.62 0.00 幂次方模型 Y=6.147X11.378 0.74 0.71 28.26 0.00 对数模型 Y=5.473+4.801ln(X1) 0.73 0.70 27.30 0.00 逆函数模型 Y=8.198−3.112/X1 0.72 0.70 26.00 0.00 注:X1为植被指数NDVI;X2为RVI;X6为遥感影像第4波段灰度值
下载: 导出CSV
表 7 实测样地碳储量状况
Table 7 Measured carbon storage status of sample plots
样地数 碳密度/(t·hm−2) 统计值 变异系数 最小值 最大值 均值 标准差 18 87.5 3.09 4.39 3.5 0.35 0.09
下载: 导出CSV
表 8 不同树种(组)碳储量具体分布
Table 8 Specific distribution of carbon storage in different tree species (groups)
树种 碳储量/t 百分比/% 样本量/棵 马尾松 27.82 44.17 318 栎树 26.56 42.16 365 香樟 3.72 5.92 14 青冈 3.09 4.92 114 其他阔叶树 1.78 2.83 47
下载: 导出CSV
-
Fang J Y, Chen A P, Peng C H, et al. 2001. Changes in forest biomass carbon storage in China between 1949 and 1998[J]. Science, 292(5525): 2320−2322. doi: 10.1126/science.1058629
Moazzam N S. 2010. Estimation of carbon stocks in subtropical managed and unmanaged forests of Pakistan[C]//Thirteenth Sustainable Development Conference (SDC) 21-23 December 2010, Islamabad, Pakistan. DOI: 10.1016/0167-5087(84)90186-8.
Nandal A, Yadav S S, Rao A S, et al. 2023. Advance methodological approaches for carbon stock estimation in forest ecosystems[J]. Environmental Monitoring and Assessment, 195(2): 315. doi: 10.1007/s10661-022-10898-9
Pan Y, Birdsey R A, Fang J, et al. 2011. A large and persistent carbon sink in the world’s forests[J]. Science, 333(6045): 988−993. doi: 10.1126/science.1201609
Planck N R V, MacFarlane D W. 2015. A vertically integrated whole−tree biomass model[J]. Trees, 29: 449−460
Pragasan L A. 2022. Tree carbon stock and its relationship to key factors from a tropical hill forest of Tamil Nadu, India[J]. Geology, Ecology, and Landscapes, 6(1): 32−39. doi: 10.1080/24749508.2020.1742510
Qiao Y, Zheng G, Du Z, et al. 2023. Tree−species classification and individual−tree−biomass model construction based on hyperspectral and LiDAR data[J]. Remote Sensing, 15(5): 1341. doi: 10.3390/rs15051341
Sun W, Liu X. 2020. Review on carbon storage estimation of forest ecosystem and applications in China[J]. Forest Ecosystems, 7(1): 1−14. doi: 10.1186/s40663-019-0212-0
Wei M, Jiao L, Zhang P, et al. 2023. Spatio−temporal diversity in the link between tree radial growth and remote sensing vegetation index of qinghai spruce on the northeastern margin of the tibetan plateau[J]. Forests, 14(2): 260. doi: 10.3390/f14020260
Yang F, Jiang X, Ziegler A D, et al. 2023. Improved Fine−Scale Tropical Forest Cover Mapping for Southeast Asia Using Planet−NICFI and Sentinel−1 Imagery[J]. J. Remote Sens., 3: Article 0064.
鲍宽乐, 许文波, 王庆同. 2023. 基于机器学习的Landsat数据地层信息提取——以西南天山柯坪地区为例[J]. 地质通报, 42(4): 637−645. 曹海翊, 邱心怡, 贺涛. 2022. 森林生物量遥感卫星发展综述[J]. 光学学报, 42(17): 402−409. 丁增发. 2014. 安徽亚热带常绿阔叶林甜槠等4个优势树种的生物量模型及生长模型[J]. 安徽农业大学学报, 41(5): 859−865. 葛婧, 彭建松. 2023. 城市绿地碳储量估算方法分析[J]. 现代园艺, 46(12): 179−184. doi: 10.3969/j.issn.1006-4958.2023.12.059 苟睿坤, 陈佳琦, 段高辉, 等. 2019. 基于GF-2的油松人工林地上生物量反演[J]. 应用生态学报, 30(12): 4031−4040. 菅永峰, 韩泽民, 黄光体, 等. 2021. 基于高分辨率遥感影像的北亚热带森林生物量反演[J]. 生态学报, 41(6): 2161−2169. 李兰, 陈尔学, 李增元, 等. 2016. 合成孔径雷达森林树高和地上生物量估测研究进展[J]. 遥感技术与应用, 31(4): 625−633. 李娜, 李清顺, 李宏韬. 2021. 祁连山国家公园青海片区森林植被碳储量与碳汇价值研究[J]. 浙江林业科技, 41(2): 41−46. doi: 10.3969/j.issn.1001-3776.2021.02.007 李威, 黄玫, 张远东, 等. 2021. 中国国家森林公园碳储量及固碳速率的时空动态[J]. 应用生态学报, 32(3): 799−809. 蒙诗栎, 庞勇, 张钟军, 等. 2017. WorldView-2纹理的森林地上生物量反演[J]. 遥感学报, 21(5): 812−824. 倪欢, 牛晓楠, 李云峰, 等. 2021. 基于统计学习方法的安徽省安庆市自然资源自动化监测——以山体为例[J]. 地质通报, 40(10): 1656−1663. 潘腾. 2015. 高分二号卫星的技术特点[J]. 中国航天, 441(1): 3−9. 庞勇, 李增元, 余涛, 等. 2022. 森林碳储量遥感卫星现状及趋势[J]. 航天返回与遥感, 43(6): 1−15. 秦立厚, 张茂震, 钟世红, 等. 2017. 森林生物量估算中模型不确定性分析[J]. 生态学报, 37(23): 7912−7919. 邵文静, 孙伟伟, 杨刚. 2021. 高光谱遥感影像纹理特征提取的对比分析[J]. 遥感技术与应用, 36(2): 431−440. 汤旭光, 刘殿伟, 王宗明, 等. 2012. 森林地上生物量遥感估算研究进展[J]. 生态学杂志, 31(5): 1311−1318. 汤煜, 石铁矛, 卜英杰, 等. 2020. 城市绿地碳储量估算及空间分布特征[J]. 生态学杂志, 39(4): 1387−1398. 王东明, 田世攀, 张昱,等. 2021. 森林-沼泽浅覆盖区地质填图方法试验——以黑龙江1∶5万望峰公社幅为例[J]. 地质通报, 40(5): 782−797. 乌迪, 巫明焱, 陈佳丽,等. 2019. 基于Landsat影像的梭磨乡冷杉林地上碳储量估测及其时空动态[J]. 生态科学, 38(1): 111−122. 魏吉鑫, 刘斯文, 李海潘, 等. 2020. 江西赣州废弃离子型稀土矿修复区植被高光谱特征与健康状况评价[J]. 地质通报, 39(12): 2037−2043. doi: 10.12097/j.issn.1671-2552.2020.12.017 巫明焱, 董光, 王艺积,等. 2020. 川西米亚罗自然保护区森林地上碳储量遥感估算[J]. 生态学报, 40(2): 621−628. 徐丽华, 张结存, 黄博, 等. 2014. 基于QuickBird影像的城市森林碳储量遥感估测[J]. 应用生态学报, 25(10): 2787−2793. 续珊珊. 2014. 森林碳储量估算方法综述[J]. 林业调查规划, 39(6): 28−33. 岳春宇, 郑永超, 庞勇, 等. 2020. 卫星林业遥感系统及应用[J]. 卫星应用, 106(10): 51−55. doi: 10.3969/j.issn.1674-9030.2020.10.013 殷鸣放, 杨琳, 殷炜达,等. 2010. 森林固碳领域的研究方法及最新进展[J]. 浙江林业科技, 30(6): 78−86. doi: 10.3969/j.issn.1001-3776.2010.06.018 张桂莲, 邢璐琪, 张浪, 等. 2022. 城市绿地碳汇计量监测方法研究进展[J]. 园林, 39(1): 7. 张梦顺. 2022. 高光谱遥感影像中纹理特征的作用[J]. 工程技术研究, 7(12): 219−221. doi: 10.12361/2705-0513-04-12-105869 郑吉林, 蔡艳龙, 郭晓宇,等. 2024. 基于InVEST模型的晋北土地利用变化与碳储量研究[J]. 地质通报, 43(1): 173−180. -
期刊类型引用(0)
其他类型引用(1)









计量
- 文章访问数: 1165
- HTML全文浏览量: 450
- PDF下载量: 1260
- 被引次数: 1
