
Distribution of shallow gas at an offshore platform site in Bohai Bay and its genetic mechanism
-
摘要:
海底浅层气严重影响海底地层的结构稳定性,因此成为影响近海海洋平台安全的重要因素。基于高精度浅地层剖面及单道地震等物探调查资料,识别了渤海湾某海洋平台周边的浅层气分布状况及顶界埋深,并分析了研究区浅层气的成因。浅地层和单道地震资料解释的浅层气分布和顶界埋深具有非常好的一致性,平台周边1 km2范围内的浅层气主要分布在平台北侧及紧贴平台西南角,呈片状或条状分布,局部呈点状分布,顶界埋深在0.6~4.0 m之间。研究区内浅层气为浅层生物成气,但该区域断层发育,不排除热解成因浅层气的存在。指出浅层气体对海洋平台的影响主要表现在变形和失稳2个方面,对海洋平台采取针对性的防护措施具有现实意义。
Abstract:Submarine shallow gas has a serious impact on the structural stability of seafloor strata, so it has become an important factor affecting the safety of offshore platforms.Based on high-precision shallow stratigraphic profiles and single channel seismic data, the distribution and top buried depth of shallow gas around an offshore platform in Bohai Bay were identified, and the origin of shallow gas in the study area was analyzed.The distribution of shallow gas interpreted by shallow strata and single channel seismic data is very consistent with the top buried depth.The shallow gas in the area of 1 km2 around the platform is mainly distributed in its north side and adjacent to its southwest corner in the form of patches or strips and locally in the form of points.The burial depth of top boundary is between 0.6 m and 4.0m.The shallow gas in the study area is shallow biogenic gas, but the fault development in this area does not rule out the existence of pyrolytic shallow gas.The influence of shallow gas on offshore platform is mainly manifested in two aspects of deformation and instability.This conclusion has practical significance for taking targeted protective measures for offshore platform.
-
Keywords:
- Bohai Bay /
- offshore platform /
- shallow gas /
- distribution /
- genetic mechanism
-
地质数据是地质工作中形成的重要信息资源,多年累积形成的海量地质数据信息为国民经济和社会发展提供了重要支撑[1]。地质行业历史悠久,地质资料积累丰厚[2],因此,实现海量地质数据存储具有重要的现实意义。中国的地质数据库建设工作自20世纪80年代中后期起步,时间上晚于西方国家。目前为止,建立的地质数据库主要包括油气及固体矿产资源勘探、地质环境调查、水文地质、矿产资源潜力评价等内容,数量也已经具有一定的规模[3],采取的方法主要为关系数据库。张博[4]以ArcGIS为基础信息系统,通过ArcCatalog自带功能,建立基于Personal Geodatabase的陕西府谷县地质灾害空间数据库。蒲凯[5]在创建地质空间数据库系统时,把Oracle当做存储管理所有空间数据的基础工具,在ArcSDE的支持下,实现了空间数据的统一存储和管理,并进行应用示范。刘灿娟[6]在Microsoft Visual Studio.NET环境下,结合Oracle 10G数据库系统相关技术,根据应用要求,设计并完成地质数据的存储管理工作。然而,数据的不断积累,海量数据的出现,使得通用的关系型数据库无法很好地应对数据规模剧增时系统扩展性和性能问题,Hadoop的出现,则很好地解决了大数据存储的问题。由于Hadoop处理过程主要是通过Hadoop分布式文件系统(HDFS)来实现的[7], 因此本文采用Hadoop中的HDFS为底层存储架构,HBase为元数据存储机制的方式存储地质矿产大数据。实验证明,该存储方式明显优于传统关系数据存储方式。
1. Hadoop系统框架
地质数据具有多源、多元、异构、时空性、方向性、相关性、随机性、模糊性、非线性等特性[8],因此地质大数据具有多样性,存在多维度、结构化与非结构化并用的特点。HDFS[9]作为Hadoop的分布式文件系统,可用于保存基本是顺序访问的海量结构化、非结构化等数据,并且适合运行在普通硬件上[10],而HBase的主要优势为快速随机访问数据。因此,只有将两者结合起来才能更好地实现影像、矢量、文本等海量地质矿产数据的存储与检索。本文存储方法设计如下:将实际地质矿产数据存储到HDFS中(对于存储大的(基于MB、GB)影像地质数据条目直接存储到HDFS中,小的(KB)文本、矢量地质数据条目,先进行小文件合并等措施,再存储到HDFS中),HBase存储其索引数据。应用程序在一个新的HDFS文件中写入结果,同时更新基于HBase的元数据。
Hadoop为用户提供了一个开源的大数据分布式处理框架,包括分布式文件系统HDFS、分布式处理模型MapReduce、非关系型数据库HBase,该框架帮助用户在了解底层实现的基础上,通过函数编程和操作接口,完成对大数据的存储和处理[11]。其系统框架如图 1所示。
(1)HDFS:分布式文件系统,在整个软件生态系统中提供数据存储的功能,并提供数据的流式访问接口,相比集中式数据存储机制,它可以有效地提高系统数据访问的吞吐量。HDFS部署在一个由大量普通PC服务器组成的集群中,采用一次写入、多次读取的文件访问模型,并具有很强的容错处理能力和良好的平台可移植性。
(2)MapReduce:一个处理大数据的编程模型[12],采用Map和Reduce两个简化过程将复杂的任务分成相互独立的子问题,并自动调度计算处理节点来处理这些子问题。利用数据/代码互定位技术有效地减少节点间的数据通信,还能够为应用开发者隐藏系统层的功能实现细节。
(3)HBase:一种提供列存储、实时读写,高性能的分布式数据库,是非关系型数据库NoSQL的一种具体实现,用于存放非结构化和半结构化的松散数据,并且可以通过主键(RowKey)和主键range来实现检索功能。
2. 地质矿产大数据存储模型
2.1 基于关系型数据库的存储模型
关系型数据库指采用关系模型来组织数据的数据库,模型由IBM研究员Codd在1970年首次提出[13]。地理信息系统(Geographic Information System, 简称GIS)以计算机科学为主要支撑技术,专门针对空间数据的应用问题[14],能够用于地质数据的查询管理、空间分析、可视化等操作,将其与Oracle大型空间数据库结合并基于一定的标准进行数据库系统开发,是海量地质数据存储管理的现有存储方案。近半个世纪以来,中国针对国家级基础地质数据库的投资种类达到上百种,投资的数据总量也已超过100TB,并且目前数量还在急剧增长[15]。这些数据管理大多以GIS为基础实现平台,集合大型数据库存储技术、计算机技术进行组织、生产和展示,部分甚至采取三维建模等技术进行一体化管理。然而,这些管理应用中很少能充分利用数据库的功能,因此,面对海量数据的存储,将变得不堪重负。
2.2 基于非关系型数据库的存储模型
随着地质数据的快速增长,基于关系型数据库的存储模式已经很难高效地满足大量地质数据的存储要求。目前,云平台的出现及“大数据”的发展使得越来越多的学者倾向于运用Hadoop相关技术进行数据存储的研究。本文目标是结合HDFS与HBase的优点,设计一个复合式的地质大数据存储系统,将原始地质数据资料存储在HDFS中,将地质矿产元数据存储于HBase中,以实现大数据存储与高效率检索,系统架构如图 2所示。
HDFS主要由NameNode和一系列DataNode组成,其体系结构见图 3,其中,NameNode和Secondary NameNode协同合作管理HDFS的目录树和相关的元数据文件。NameNode的fsimage是元数据镜像文件,存储着整个文件系统的目录树,edits则是元数据的操作日志,且其大小影响NameNode的启动和运行速度,所以需要Secondary NameNode定期通过http get从NameNode中获取上述2个文件,并合并生成新的fsimage文件返回给NameNode,随后NameNode更新本地的fsimage文件,并清空edit操作日志内容,从而提升HDFS节点管理性能[16]。
2.2.1 基于HDFS的地质大数据存储
HDFS的文件操作主要包括读、写2个主要流程,两者均由HDFS客户端发起。
(1)文件写入:①客户端通过调用Distributed File System对象中的create()方法,初始化写入文件实例。②NameNode首先会验证系统中没有要创建的文件,并确保客户端有创建文件的权限,否则会抛出I/O异常。③若校验通过,FSData Output Stream会将文件切割成多个packets,并协调NameNode和DataNode,通过write packet方法将对象写入DataNode。④最后一个文件写入成功后会返回一个ack packet给客户端,客户端则调用close方法关闭所有数据流,并将完成的信息汇报给NameNode。
本文选取重庆市矿产潜力评价数据中的“重庆市城口南大巴山式侵入岩型金矿预测工作区遥感影像图GEOTIFF”(230MB)为测试数据将其存储到HDFS中,核心代码如下:
FSDataOutputStream fsDataOutputStream = fs. create(new Path(“/opt/hadoop/dfs/Data/重庆市/金矿/重庆市城口南大巴山式侵入岩型金矿预测工作区遥感影像图GEOTIFF.tif”));//在hdfs上打开一个文件输出流FileInputStream fileInputStream = new FileInputStream(“/home/hadoop/Desktop/重庆市城口南大巴山式侵入岩型金矿预测工作区遥感影像图GEOTIFF.tif”);//在hdfs上打开一个文件输入流IOUtils.copy(file Input Stream,fs Data Output Stream)。
(2)文件读取:①客户端调用open函数,向远程的NameNode发起RPC请求,调用元数据节点,得到文件的数据块信息。②客户端在打开的文件流上调用read()函数。DFSInputStream连接保存距离此文件最近的DataNode,并把要读的数据返回客户端。③读取完当前block的数据后,就会断开到DataNode的链接,然后选择下一个DataNode来获取下一个数据块。④所有数据读取完毕后,调用close函数来关闭数据流。
本文选取hdfs中data下的矢量数据为读取对象,核心代码如下:
RemoteIterator <LocatedFileStatus> listFiles = fs.listFiles(new Path(“/opt/hadoop/dfs/data”), true);
While(ListFiles.hasNext()){
LocatedFileStatus file = ListFiles.next();
System.out.println(file.getPath().getName()); }
2.2.2 基于HBase的地质元数据存储
HBase是一个分布式的、面向列的开源数据库,是基于Google论文《Bigtable:A distributed storage syatems for structured data》 [17]开源实现,HBase将HDFS作为其底层存储系统;以HadoopMapReduce进行海量数据分析;采用Zookeeper进行数据的统一管理。
以矢量地质数据为例,本文采用每个省份数据作为一个表,每个矿种对应一行,用行健表示各省份对应的矿种信息;用不同的列族代表“综合研究成果资料”、“省级矿产资料”;用不同的列代表不同的要素图(表 1)。
表 1 HBase列式存储设计Table 1. HBase column storage design table行健 时间戳 列族SPE 列族S_SPE 矿种ID 专题ID 图件ID 路径 其他属性 矿种ID 专题ID 图件ID 路径 其他属性 矿种RowKey TimeStamp MID SID FID LCT … MID SID FID LCT … 在表中,列族“SPE”代表“综合研究成果资料”,列族“S_SPE ”代表“省级矿产资料”。列族“SPE”下的‘MID’代表矿种的编码信息(编码信息由国家统一规定),如01代表“铁”,02代表“锰”等,后面命名规则参照前述方式。该事例表示的为“湖南省硫矿种”的编码信息和存储路径信息:
4319 column=SPE: MID, timestamp= 1478462443280, value=4319
4319 column=SPE: LCT, timestamp= 1478462443280, value=hdfs://192.168.20.51/opt/
hadoop/dfs/data/HUNAN
2.3 小文件存储问题
HDFS是一个具有高容错性、成本低廉性等特点的分布式文件系统,被设计用来对大文件进行流式存储,而在处理小文件时则会产生一些问题[18]。地质空间数据与其他空间数据相比,具有数据量大、专题内容多、信息量大等特点,且以矢量图层、遥感影像等大文件数据为主,非常适合于HDFS存储方法。以重庆市的金矿种为例,矿产潜力评价数据如图 4。
![]() 图 4 潜力评价数据(以重庆市金矿种为例)Figure 4. Potential evaluation data exemplified by a gold mine in Chongqing
图 4 潜力评价数据(以重庆市金矿种为例)Figure 4. Potential evaluation data exemplified by a gold mine in Chongqing经实验发现,矢量图层存储时并非以各地区的“图件”为存储单元存储到一个至几个Block内存中,而是以WL、WT等文件单独进行存储,分别占据一个Block内存,形成无数小文件,造成HDFS存储瓶颈(图 5)。
图 4显示“重庆市城口石门口南大巴山岩浆热液型金矿区典型成矿要素图”中的一个矢量要素。该图只有15892个字节,却占据了一个Block节点,分配单独的split,给集群带来了存储压力。
2.4 Hadoop自带小文件优化方案
对于小文件问题,Hadoop系统自身提供了3个解决方案,分别是Hadoop Archive[19],Sequence File[20],CombineFileInputFormat。
HAR(Hadoop Archive)文件归档技术主要通过将HDFS上的小文件打包成HAR,缓解大量小文件消耗NameNode内存的问题。但是读取HAR中的文件需要读取两层index文件及文件本身数据,且HAR不支持存档文件的压缩,因此使用HAR处理小文件效率较低。
SequenceFile是HDFS提供的一种二进制文件技术,通过 <key, value>对序列化到SequenceFile文件实现多个小文件合并,同时支持数据块的压缩,显著减少了NameNode的内存及数据节点的磁盘空间。然而该方法没有建立相应的小文件到大文件的映射,读取效率低。
CombineFileInputFormat是一种新的输入格式,将HDFS上的多个文件合并成一个单独的split进而提高效率。该方法适用于HDFS中已经存在大量小文件的情况,并且CombineFileInputFormat是一个抽象类,需要用户自己实现实体类。
参考以上方法,CombineFileInputFormat方案更可行,然而,大量小文件数据尚未存到Hadoop平台,若先进行存储,再优化,效率则更低,所以最理想的策略是将“图层”下的各矢量因素合并为一个大文件,以此来提高小文件的存储性能。
2.5 IPutMerge解决方案
针对HDFS小文件存储,《hadoop实战》 [21]提供了一个PutMerge程序,用于将本地磁盘文件合并,然后再复制到HDFS。然而该方案仅面向本地单个文件夹下的数据,对于大量不同路径的数据存储,效率则较低,因此,本文设计了一种IputMerge(Improved PutMerge)程序,该方法可以实现数据的跨路径存储,操作更便捷。
管理split的总时间和构建map任务的总时间决定作业的执行时间,因此合理的分片大小决定负载平衡的质量,本文将分片大小设置为Block的大小128MB。其次,调用Configuration conf得到所需要的FileSystem实例。Configuration对象封装了客户端或服务器的配置,通过设置配置文件读取类路径实现core-site.xml。有了FileSystem实例后,调用factory方法FileSystem.getLocal(Configuration conf)。Hadoop文件API使用Path对象编制文件和目录名,使用FileStatus对象存储文件和目录的元数据。IPutMerge程序将调用递归算法合并本地不同目录中的所有文件。使用FileSystem的ListStatus()方法得到本地的目录。FSDataInputStream是Java标准类java.io.DataInputStream的子类,可以提供随机访问的功能,本文用该方法将数据写入HDFS。为实现IPutMerge,创建一个for循环逐一读取inputFiles中的所有文件。部分代码如下所示:
Configuration conf = new Configuration();
......
Path localPath = new Path((“/home/hadoop/Desktop/重庆市/金矿典型矿床成矿要素图”));
Path hdfsPath = new Path((“/opt/hadoop/dfs/data/重庆市/金矿种潜力评价图库/矿产及其预测/金矿典型矿床成矿要素图”));
if(out==null){
out = hdfsFS.create(hdfsPath);
}
readLocalFileWriteToHDFS(localPath, localFS);
......
FileStatus[] inputFiles = localFS.listStatus(localPath);
for(int i =0; i < inputFiles.length; i++){
boolean isDir = inputFiles[i].isDirectory();
if(isDir){
readLocalFileWriteToHDFS(inputFiles[i].getPath(), localFS);
}
if(inputFiles[i].isFile()){
……
}
}
}
最后,调用MapReduce程序,将数据上传到HDFS之上。Shell命令为:
[hadoop@hdmaster1 Desktop] $ hadoop jar HDFSpd.jar数据.HDFSpd2
3. 实验验证
3.1 小文件优化对比实验
为了验证优化后的方案更具优势,本文从2个方面进行对比测试:①实验数据在HDFS上的写入性能;②文件操作过程中HDFS的NameNode内存占用结果。
(1)实验环境
本文实验采用4个节点的Hadoop集群,其中包括1个NameNode和3个DataNode,具体配置如表 2。
表 2 集群配置情况Table 2. Cluster configuration组件 配置 Hadoop版本 Hadoop2.7.2 操作系统 Red Hat Enterprise Linux Server release 6.7(Santiago) Linux内核版本 2.6.32-573.e16.x86_64 JDK 1.7.0_91 网络带宽 100MB NameNode 八核2.4.0GHzCPU, 16G内存,600G硬盘,数量1 DataNode 八核2.4.0GHzCPU, 8G内存,600G硬盘,数量3 (2)写操作性能对比测试
本实验分别选取500, 1000, 10000, 20000, 30000, 40000个大小为1~1000KB的小文件为存储数据,分别进行数据存储,记录它们各自的存储时间,取3次实验结果的平均值,实验结果见图 6。
图 6表明,采用IPutMerge方法优化后的HDFS的写操作明显快于原始HDFS。这是因为,每写入一个文件到HDFS,NameNode都要对其进行创建和分配数据块的操作,而本文优化后的HDFS中,当n个小文件组成的大文件写入时,NameNode仅被调用一次。另外,Client对大文件使用的缓存机制,每128MB数据的请求被发送到NameNode,而不是发送每个小文件。
(3)内存占用对比测试
海量小文件会耗费主节点内存,造成NameNode瓶颈问题,进而严重影响HDFS的性能,为了分析基于HDFS的分布式文件存储系统中的NameNode占用情况并设计实验。
本实验分别选取500, 1000, 10000, 20000, 30000, 40000个大小为1~1000KB的小文件作为实验数据,在半小时内不断写入各文件到HDFS,并观察NameNode所占系统内存变化,取3次实验结果的平均值。内存使用量结果如图 7所示。
图 7显示了2种情况下的内存使用情况,从结果可以看出,在小文件数量小于1000个的情况下,优化效果并不明显,然而随着小文件数量的急剧增长,优化后的NameNode所占内存量远远低于优化前的HDFS中。这是因为,NameNode主要保存文件元数据及文件所在块的元数据。优化前的HDFS进行数据存储时,每个小文件占据了一个Block,则NameNode需占用大量内存来保存这些数据。而优化后的HDFS,NameNode保存了单个组合文件及Block的元数据,因此,系统内存占用量则会大幅度降低。
3.2 Hadoop与Oracle对比实验
本文实验通过对比2种空间数据存储方式:①传统空间数据存储方式,即采用Oracle与MapGis相结合进行空间数据存储。② Hadoop平台,通过HDFS进行数据存储。分析实验结果,验证本文方法更具优势。
(1)实验环境
表 3给出了测试用到的硬件环境,其中Oracle采用单节点,Hadoop则是在4台电脑上部署的集群。
表 3 测试数据库硬件环境Table 3. Test database hardware environment组件 Oracle Hadoop 操作系统 Windows7专业版 Red Hat Enterprise Linux Server release 6.7(Santiago) 服务器数量 1台(单节点) 4台(Hadoop集群) 网络带宽 100MB 100MB CPU性能 四核 八核 CPU主频 2.80GHz 2.40GHz 内存 8GB 8GB (2)数据导入对比实验
本实验以重庆市矿产资源潜力评价数据作为研究对象,选取100, 1000,10000, 50000, 100000个大小为1~1000KB的小文件为存储数据,分别采用Oracle与Hadoop先后进行数据存储,求取3次对比实验结果的平均值(图 8)。
从图 8可以看出,当文件数量较少时,2种存储方式效率持平,改进后的Hadoop存储方式则略占优势;当数据量很少时,较之传统的Hadoop存储,Oracle效率可能更高,这是因为使用Hadoop进行数据存储时,涉及到NameNode的元数据存储及DataNode的选取,耗费时间较长,优化后的Hadoop则仅需要调用少量的NameNode,大大节省了系统开销时间;当数据量较大时,尤其达到10000个以后,Hadoop在地质数据存储方面则显示出了巨大优势,写入数据所需时间大为缩短。而传统的Oracle数据库,数据存储由于主要集中在一台物理存储节点上,随着数据量不断增加大致呈线性增长。
3.3 数据导出对比实验
本实验以重庆市矿产资源潜力评价数据作为研究对象,选取100, 1000,10000, 50000, 100000个大小为1~1000KB的小文件为研究数据,将Oracle与Hadoop中存储的数据分别进行下载,记录它们各自的响应时间,对比3次实验结果,求取其平均值。
对比2种方式,从实验结果(图 9)可以看出,在数据量很小时,使用Hadoop进行数据读取并没有太大优势,比起传统Oracle仅略占优势。这是因为,当数据量少时,Hadoop本身的系统开销需要花费更多的数据处理时间,然而改进后的Hadoop将多个小文件合并为一个大文件,大大减少了访问数据量。因此,比起存储小数据量更占优势的Oracle来说,效率还要稍高。当数据量大幅度上升时,尤其数据量超过10000个时,Oracle的单节点数据输出则较吃力,系统响应时间大致呈线性增长,而Hadoop的多节点并行工作突显出了更大的优势。
4. 结语
大数据时代的到来带动了地质大数据的发展,而地质数据对城市规划、建设、安全等都具有重要的指导意义,如何有效存储地质数据成为了亟待解决的现实问题。本文针对海量地质矿产数据的存储问题,提出了一种全新的数据存储方案,对地质行业的发展具有一定的参考价值。实验表明:
(1)HDFS不适合海量地质小文件的存储,而优化后的HDFS数据存储则具有显著优势;
(2)当数据量很少时,基于Hadoop的存储效率优势并不明显,而当数据量急剧增长时,Hadoop则展示出了海量数据的存储优势;
(3)本文提出的方案是有效的,为地质数据的存储与管理提供了一种可行的技术方案。
致谢: 野外调查作业期间得到自然资源部第一海洋研究所胡光海研究员的大力支持和指导,数据处理和成文过程得到了自然资源部第一海洋研究所赵晓龙的帮助,在此一并表示感谢。 -
![]()
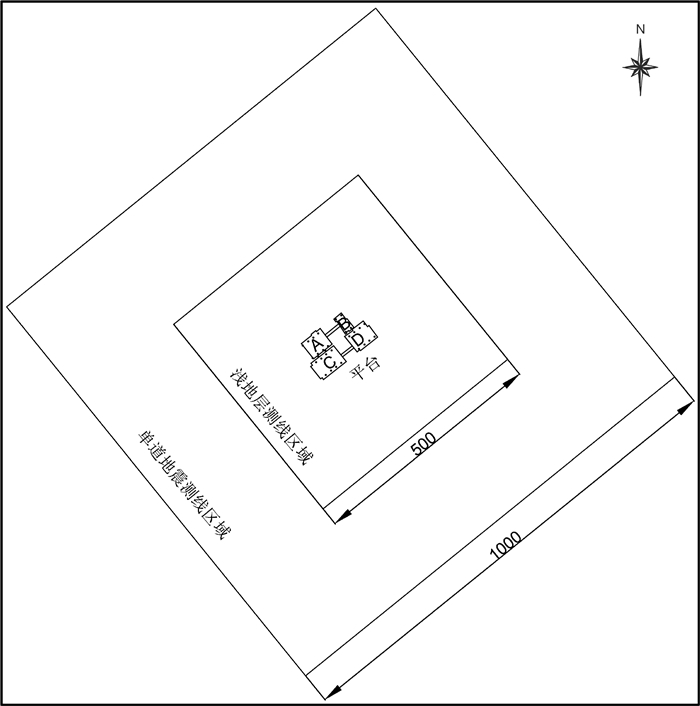
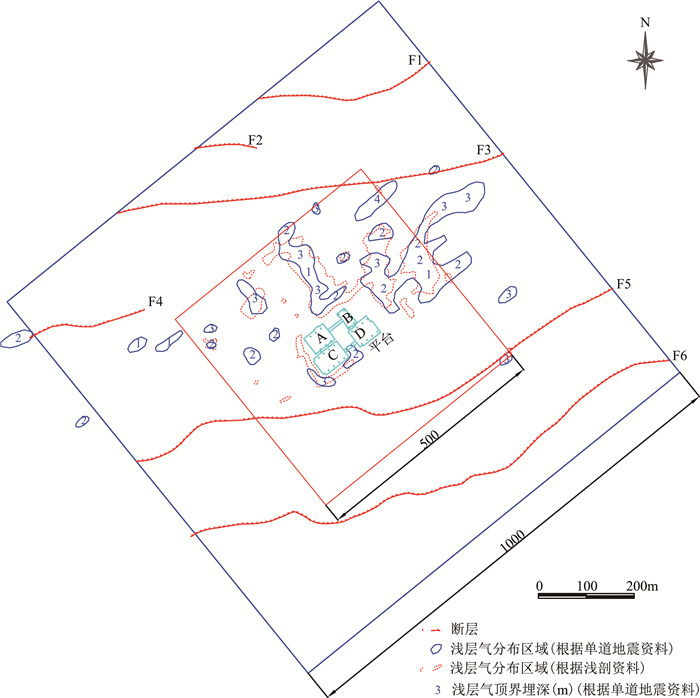
图 2 研究区海洋平台及调查范围示意图
(单位:m)
Figure 2. Location of the offshore platform showing its investigation area
![]()
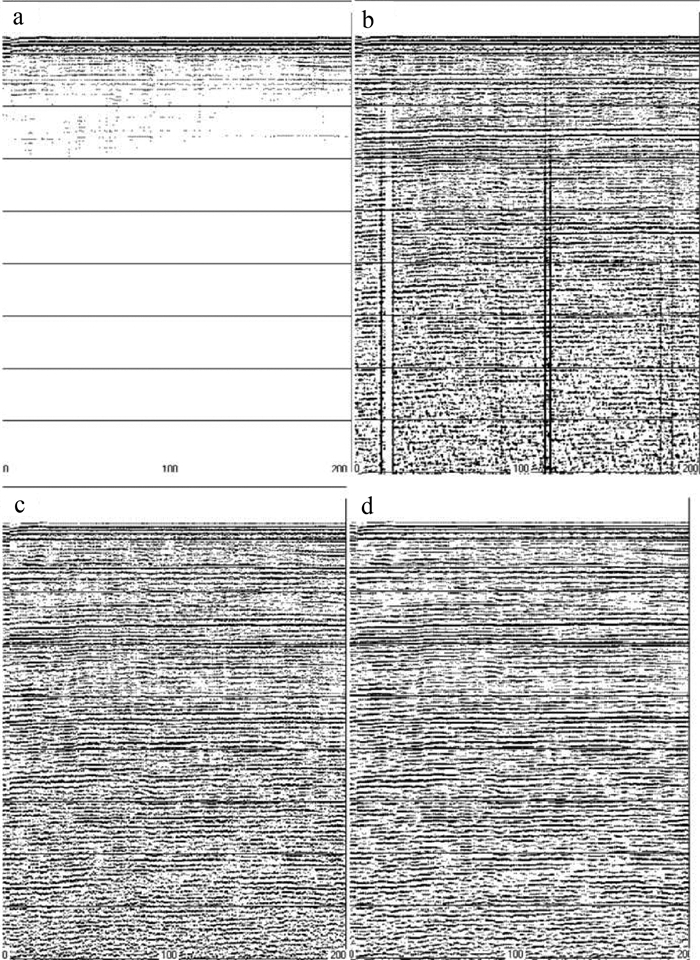
图 3 SES 2000极浅地层剖面系统(a、b)及SIG Pulse L5单道数字地震仪(c、d)
Figure 3. The SES 2000 extremely sub-bottom profile system (a, b) and the SIG Pulse L5 Single-channel digital seismograph (c, d)
![]()
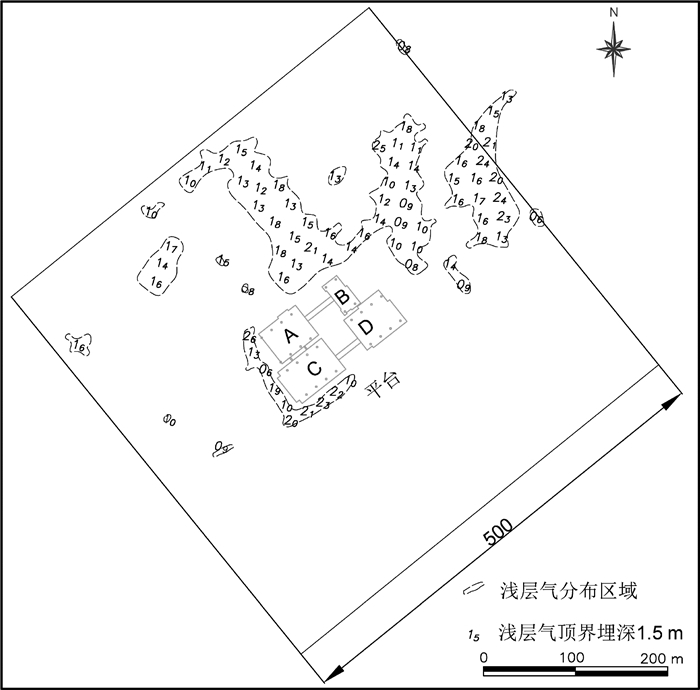
图 6 平台周边0.5 km×0.5 km浅层气分布及顶界埋深
(依据浅地层剖面探测)
Figure 6. Distribution of shallow gases around the platform its top buried depth of the top boundary
![]()
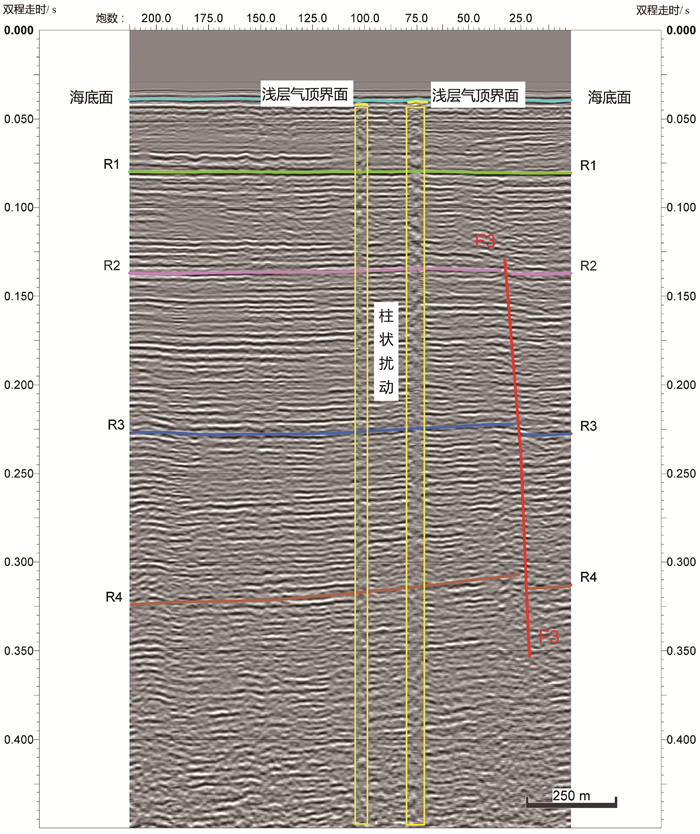
图 7 典型单道地震剖面结果
(R1-R4为识别的地层,F3为识别的断层)
Figure 7. Typical shallow gas profile detected by single-channel profile
-
Floodgate G D, Judd A D. The origins of shallow gas[J]. Continental Shelf Research, 1992, 12(10): 1145-1156. doi: 10.1016/0278-4343(92)90075-U
李萍, 杜军, 刘乐军, 等. 我国近海海底浅层气分布特征[J]. 中国地质灾害与防治学报, 2010, 21(1): 69-74. doi: 10.3969/j.issn.1003-8035.2010.01.015 邢磊, 焦静娟, 刘雪芹, 等. 渤海海域浅层气分布及地震特征分析[J]. 中国海洋大学学报, 2014, 47(11): 71-78. https://www.cnki.com.cn/Article/CJFDTOTAL-QDHY201711010.htm Young-Jun K, Snons C, Jong-Hwa C, et al. Identification of shallow gas by seismic data and AVO processing: Example from the southwestern continental shelf of the Ulleung Basin, East Sea, Korea[J]. Marine and Petroleum Geology, 2020, 117, DOI: 10.1016/j.marpetgeo.2020.104346.
秦芹. 南海北部白云凹陷浅层气的地球物理识别、成因和运移模式的研究[D]. 中国科学院深海科学与工程研究所硕士学位论文, 2017. Hagen R A, Vogt P R. Seasonal variability of shallow biogenic gas in Chesapenke Bay[J]. Marine Geology, 1999, 158(1): 75-88. http://www.sciencedirect.com/science/article/pii/S0025322798001856
Sauter E J, Muyakshin S I, Charlou J L, et al. Methane discharge from a deep-sea submarine mud volcano into the upper water column by gas hydrate-coated methane bubbles[J]. Earth and Planetary Science Letters, 2006, 243(3): 354-365. http://www.sciencedirect.com/science/article/pii/S0012821X0600077X
吴时国, 孙运宝, 李清平, 等. 南海深水地质灾害[M]. 北京: 科学出版社, 2019: 154-163. 杨鸿波, 齐恒之. 渤海油田浅层气井喷预防及控制技术[J]. 中国海上油气, 2004, 16(1): 43-46. doi: 10.3969/j.issn.1673-1506.2004.01.008 谭振华, 陈红, 沙东, 等. 大港滩海(浅海)区浅层气井喷原因分析及预防技术探讨[J]. 天然气地球科学, 2005, 16(3): 369-373. doi: 10.3969/j.issn.1672-1926.2005.03.024 夏真, 马胜中, 石要红. 伶仃洋海底浅层气的基本特征[J]. 第四纪研究, 2006, 26(3): 456-461. doi: 10.3321/j.issn:1001-7410.2006.03.019 叶银灿. 中国海洋灾害地质学[M]. 北京: 海洋出版社, 2012. 汪泽成, 刘和甫, 段周芳, 等. 黄骅坳陷中新生代构造负反转分析[J]. 地球科学, 1998, 23(3): 289-293. doi: 10.3321/j.issn:1000-2383.1998.03.015 李岳桐, 王文庆, 王刚, 等. 渤海湾盆地黄骅坳陷新构造运动特征及其控藏作用[J]. 东北石油大学学报, 2019, 43(6): 94-104. https://www.cnki.com.cn/Article/CJFDTOTAL-DQSY201906011.htm 李延成. 渤海的地质演化与断裂活动[J]. 海洋地质与第四纪地质, 1993, 13(2): 25-33. https://www.cnki.com.cn/Article/CJFDTOTAL-HYDZ199302003.htm 叶银灿, 陈俊仁, 潘国富, 等. 海底浅层气的成因、赋存特征及其对工程的危害[J]. 东海海洋, 2003, 21(1): 27-36. https://www.cnki.com.cn/Article/CJFDTOTAL-DHHY200301005.htm 琼斯, 金翔龙. 海洋地球物理[M]. 北京: 科学出版社, 2010. 田立柱. 渤海湾西北部浅表地层结构特征[D]. 吉林大学硕士学位论文, 2007. 杨子赓, 张志询, 王学言. 渤海湾北部浅海海洋地质环境演变与灾害地质问题[C]//寸丹集——庆贺刘光鼎院士工作50周年学术论文集. 1998. 钟方杰, 朱建群. 应用持水特征曲线预测浅层气藏压力[J]. 施工技术, 2007, 36(S): 494-496. https://www.cnki.com.cn/Article/CJFDTOTAL-SGJS2007S1173.htm 郁孟龙. 东海沿海浅层气体对水利工程的危害及防治措施[J]. 中国水利, 2011, 16: 37-40. https://www.cnki.com.cn/Article/CJFDTOTAL-SLZG201116019.htm

 下载:
下载:










计量
- 文章访问数: 3115
- HTML全文浏览量: 579
- PDF下载量: 1723
