
Geological survey and study of fault structures in the shallowly covered Keluo area of Nenjiang County, Da Hinggan Mountains
-
摘要:
位于大兴安岭北段东坡的嫩江科洛地区属于典型的浅覆盖区。针对该区特殊的地质地貌特点,尝试利用重力和航磁技术解译和推断,结合野外露头调查和查证的综合研究方法对区域内断裂构造进行识别和应力机制分析。通过基岩出露区的验证,该方法对浅覆盖区断裂构造性质及活动特点的推断解释具有较明显的效果。因此,本文认为重磁、露头观测的综合应用,起到了相互补充、印证的效果,减少了推断结果的多解性,提升了解释成果的可靠性。为浅覆盖区地质填图、区域构造研究及成矿预测等提供了有效的技术方法支撑。
Abstract:The Keluo area of Nenjiang County, which is situated in the Nenjiang River basin on the eastern slope of northern Da Hinggan Mountains, is a typical shallowly covered area. In this paper, the authors tried to recognize fault structures and analyze their stress mechanism in the area through synthetic techniques of interpretation and deduction on gravity and aeromagnetic data combined with field outcrop survey. Based on verification of the fault structure in the exposed bedrock area, the authors hold that this synthetic method has good effect in acquiring the mechanical properties and activity characteristics of the faults under the shallowly covered area. It is therefore suggested that the synthetic application of gravity-magnetic and outcrop investigation could be mutually corroborated and, with this means, the multi-solution could be reduced, and the reliability of interpretation could be improved. In addition, such a synthetic application can provide an effective technique support for the geological mapping, regional tectonic study and metallogenic prediction in the shallowly covered area.
-
Keywords:
- Da Hinggan Mountains /
- shallowly covered area /
- fault structure /
- research method
-
地质数据是地质工作中形成的重要信息资源,多年累积形成的海量地质数据信息为国民经济和社会发展提供了重要支撑[1]。地质行业历史悠久,地质资料积累丰厚[2],因此,实现海量地质数据存储具有重要的现实意义。中国的地质数据库建设工作自20世纪80年代中后期起步,时间上晚于西方国家。目前为止,建立的地质数据库主要包括油气及固体矿产资源勘探、地质环境调查、水文地质、矿产资源潜力评价等内容,数量也已经具有一定的规模[3],采取的方法主要为关系数据库。张博[4]以ArcGIS为基础信息系统,通过ArcCatalog自带功能,建立基于Personal Geodatabase的陕西府谷县地质灾害空间数据库。蒲凯[5]在创建地质空间数据库系统时,把Oracle当做存储管理所有空间数据的基础工具,在ArcSDE的支持下,实现了空间数据的统一存储和管理,并进行应用示范。刘灿娟[6]在Microsoft Visual Studio.NET环境下,结合Oracle 10G数据库系统相关技术,根据应用要求,设计并完成地质数据的存储管理工作。然而,数据的不断积累,海量数据的出现,使得通用的关系型数据库无法很好地应对数据规模剧增时系统扩展性和性能问题,Hadoop的出现,则很好地解决了大数据存储的问题。由于Hadoop处理过程主要是通过Hadoop分布式文件系统(HDFS)来实现的[7], 因此本文采用Hadoop中的HDFS为底层存储架构,HBase为元数据存储机制的方式存储地质矿产大数据。实验证明,该存储方式明显优于传统关系数据存储方式。
1. Hadoop系统框架
地质数据具有多源、多元、异构、时空性、方向性、相关性、随机性、模糊性、非线性等特性[8],因此地质大数据具有多样性,存在多维度、结构化与非结构化并用的特点。HDFS[9]作为Hadoop的分布式文件系统,可用于保存基本是顺序访问的海量结构化、非结构化等数据,并且适合运行在普通硬件上[10],而HBase的主要优势为快速随机访问数据。因此,只有将两者结合起来才能更好地实现影像、矢量、文本等海量地质矿产数据的存储与检索。本文存储方法设计如下:将实际地质矿产数据存储到HDFS中(对于存储大的(基于MB、GB)影像地质数据条目直接存储到HDFS中,小的(KB)文本、矢量地质数据条目,先进行小文件合并等措施,再存储到HDFS中),HBase存储其索引数据。应用程序在一个新的HDFS文件中写入结果,同时更新基于HBase的元数据。
Hadoop为用户提供了一个开源的大数据分布式处理框架,包括分布式文件系统HDFS、分布式处理模型MapReduce、非关系型数据库HBase,该框架帮助用户在了解底层实现的基础上,通过函数编程和操作接口,完成对大数据的存储和处理[11]。其系统框架如图 1所示。
(1)HDFS:分布式文件系统,在整个软件生态系统中提供数据存储的功能,并提供数据的流式访问接口,相比集中式数据存储机制,它可以有效地提高系统数据访问的吞吐量。HDFS部署在一个由大量普通PC服务器组成的集群中,采用一次写入、多次读取的文件访问模型,并具有很强的容错处理能力和良好的平台可移植性。
(2)MapReduce:一个处理大数据的编程模型[12],采用Map和Reduce两个简化过程将复杂的任务分成相互独立的子问题,并自动调度计算处理节点来处理这些子问题。利用数据/代码互定位技术有效地减少节点间的数据通信,还能够为应用开发者隐藏系统层的功能实现细节。
(3)HBase:一种提供列存储、实时读写,高性能的分布式数据库,是非关系型数据库NoSQL的一种具体实现,用于存放非结构化和半结构化的松散数据,并且可以通过主键(RowKey)和主键range来实现检索功能。
2. 地质矿产大数据存储模型
2.1 基于关系型数据库的存储模型
关系型数据库指采用关系模型来组织数据的数据库,模型由IBM研究员Codd在1970年首次提出[13]。地理信息系统(Geographic Information System, 简称GIS)以计算机科学为主要支撑技术,专门针对空间数据的应用问题[14],能够用于地质数据的查询管理、空间分析、可视化等操作,将其与Oracle大型空间数据库结合并基于一定的标准进行数据库系统开发,是海量地质数据存储管理的现有存储方案。近半个世纪以来,中国针对国家级基础地质数据库的投资种类达到上百种,投资的数据总量也已超过100TB,并且目前数量还在急剧增长[15]。这些数据管理大多以GIS为基础实现平台,集合大型数据库存储技术、计算机技术进行组织、生产和展示,部分甚至采取三维建模等技术进行一体化管理。然而,这些管理应用中很少能充分利用数据库的功能,因此,面对海量数据的存储,将变得不堪重负。
2.2 基于非关系型数据库的存储模型
随着地质数据的快速增长,基于关系型数据库的存储模式已经很难高效地满足大量地质数据的存储要求。目前,云平台的出现及“大数据”的发展使得越来越多的学者倾向于运用Hadoop相关技术进行数据存储的研究。本文目标是结合HDFS与HBase的优点,设计一个复合式的地质大数据存储系统,将原始地质数据资料存储在HDFS中,将地质矿产元数据存储于HBase中,以实现大数据存储与高效率检索,系统架构如图 2所示。
HDFS主要由NameNode和一系列DataNode组成,其体系结构见图 3,其中,NameNode和Secondary NameNode协同合作管理HDFS的目录树和相关的元数据文件。NameNode的fsimage是元数据镜像文件,存储着整个文件系统的目录树,edits则是元数据的操作日志,且其大小影响NameNode的启动和运行速度,所以需要Secondary NameNode定期通过http get从NameNode中获取上述2个文件,并合并生成新的fsimage文件返回给NameNode,随后NameNode更新本地的fsimage文件,并清空edit操作日志内容,从而提升HDFS节点管理性能[16]。
2.2.1 基于HDFS的地质大数据存储
HDFS的文件操作主要包括读、写2个主要流程,两者均由HDFS客户端发起。
(1)文件写入:①客户端通过调用Distributed File System对象中的create()方法,初始化写入文件实例。②NameNode首先会验证系统中没有要创建的文件,并确保客户端有创建文件的权限,否则会抛出I/O异常。③若校验通过,FSData Output Stream会将文件切割成多个packets,并协调NameNode和DataNode,通过write packet方法将对象写入DataNode。④最后一个文件写入成功后会返回一个ack packet给客户端,客户端则调用close方法关闭所有数据流,并将完成的信息汇报给NameNode。
本文选取重庆市矿产潜力评价数据中的“重庆市城口南大巴山式侵入岩型金矿预测工作区遥感影像图GEOTIFF”(230MB)为测试数据将其存储到HDFS中,核心代码如下:
FSDataOutputStream fsDataOutputStream = fs. create(new Path(“/opt/hadoop/dfs/Data/重庆市/金矿/重庆市城口南大巴山式侵入岩型金矿预测工作区遥感影像图GEOTIFF.tif”));//在hdfs上打开一个文件输出流FileInputStream fileInputStream = new FileInputStream(“/home/hadoop/Desktop/重庆市城口南大巴山式侵入岩型金矿预测工作区遥感影像图GEOTIFF.tif”);//在hdfs上打开一个文件输入流IOUtils.copy(file Input Stream,fs Data Output Stream)。
(2)文件读取:①客户端调用open函数,向远程的NameNode发起RPC请求,调用元数据节点,得到文件的数据块信息。②客户端在打开的文件流上调用read()函数。DFSInputStream连接保存距离此文件最近的DataNode,并把要读的数据返回客户端。③读取完当前block的数据后,就会断开到DataNode的链接,然后选择下一个DataNode来获取下一个数据块。④所有数据读取完毕后,调用close函数来关闭数据流。
本文选取hdfs中data下的矢量数据为读取对象,核心代码如下:
RemoteIterator <LocatedFileStatus> listFiles = fs.listFiles(new Path(“/opt/hadoop/dfs/data”), true);
While(ListFiles.hasNext()){
LocatedFileStatus file = ListFiles.next();
System.out.println(file.getPath().getName()); }
2.2.2 基于HBase的地质元数据存储
HBase是一个分布式的、面向列的开源数据库,是基于Google论文《Bigtable:A distributed storage syatems for structured data》 [17]开源实现,HBase将HDFS作为其底层存储系统;以HadoopMapReduce进行海量数据分析;采用Zookeeper进行数据的统一管理。
以矢量地质数据为例,本文采用每个省份数据作为一个表,每个矿种对应一行,用行健表示各省份对应的矿种信息;用不同的列族代表“综合研究成果资料”、“省级矿产资料”;用不同的列代表不同的要素图(表 1)。
表 1 HBase列式存储设计Table 1. HBase column storage design table行健 时间戳 列族SPE 列族S_SPE 矿种ID 专题ID 图件ID 路径 其他属性 矿种ID 专题ID 图件ID 路径 其他属性 矿种RowKey TimeStamp MID SID FID LCT … MID SID FID LCT … 在表中,列族“SPE”代表“综合研究成果资料”,列族“S_SPE ”代表“省级矿产资料”。列族“SPE”下的‘MID’代表矿种的编码信息(编码信息由国家统一规定),如01代表“铁”,02代表“锰”等,后面命名规则参照前述方式。该事例表示的为“湖南省硫矿种”的编码信息和存储路径信息:
4319 column=SPE: MID, timestamp= 1478462443280, value=4319
4319 column=SPE: LCT, timestamp= 1478462443280, value=hdfs://192.168.20.51/opt/
hadoop/dfs/data/HUNAN
2.3 小文件存储问题
HDFS是一个具有高容错性、成本低廉性等特点的分布式文件系统,被设计用来对大文件进行流式存储,而在处理小文件时则会产生一些问题[18]。地质空间数据与其他空间数据相比,具有数据量大、专题内容多、信息量大等特点,且以矢量图层、遥感影像等大文件数据为主,非常适合于HDFS存储方法。以重庆市的金矿种为例,矿产潜力评价数据如图 4。
![]() 图 4 潜力评价数据(以重庆市金矿种为例)Figure 4. Potential evaluation data exemplified by a gold mine in Chongqing
图 4 潜力评价数据(以重庆市金矿种为例)Figure 4. Potential evaluation data exemplified by a gold mine in Chongqing经实验发现,矢量图层存储时并非以各地区的“图件”为存储单元存储到一个至几个Block内存中,而是以WL、WT等文件单独进行存储,分别占据一个Block内存,形成无数小文件,造成HDFS存储瓶颈(图 5)。
图 4显示“重庆市城口石门口南大巴山岩浆热液型金矿区典型成矿要素图”中的一个矢量要素。该图只有15892个字节,却占据了一个Block节点,分配单独的split,给集群带来了存储压力。
2.4 Hadoop自带小文件优化方案
对于小文件问题,Hadoop系统自身提供了3个解决方案,分别是Hadoop Archive[19],Sequence File[20],CombineFileInputFormat。
HAR(Hadoop Archive)文件归档技术主要通过将HDFS上的小文件打包成HAR,缓解大量小文件消耗NameNode内存的问题。但是读取HAR中的文件需要读取两层index文件及文件本身数据,且HAR不支持存档文件的压缩,因此使用HAR处理小文件效率较低。
SequenceFile是HDFS提供的一种二进制文件技术,通过 <key, value>对序列化到SequenceFile文件实现多个小文件合并,同时支持数据块的压缩,显著减少了NameNode的内存及数据节点的磁盘空间。然而该方法没有建立相应的小文件到大文件的映射,读取效率低。
CombineFileInputFormat是一种新的输入格式,将HDFS上的多个文件合并成一个单独的split进而提高效率。该方法适用于HDFS中已经存在大量小文件的情况,并且CombineFileInputFormat是一个抽象类,需要用户自己实现实体类。
参考以上方法,CombineFileInputFormat方案更可行,然而,大量小文件数据尚未存到Hadoop平台,若先进行存储,再优化,效率则更低,所以最理想的策略是将“图层”下的各矢量因素合并为一个大文件,以此来提高小文件的存储性能。
2.5 IPutMerge解决方案
针对HDFS小文件存储,《hadoop实战》 [21]提供了一个PutMerge程序,用于将本地磁盘文件合并,然后再复制到HDFS。然而该方案仅面向本地单个文件夹下的数据,对于大量不同路径的数据存储,效率则较低,因此,本文设计了一种IputMerge(Improved PutMerge)程序,该方法可以实现数据的跨路径存储,操作更便捷。
管理split的总时间和构建map任务的总时间决定作业的执行时间,因此合理的分片大小决定负载平衡的质量,本文将分片大小设置为Block的大小128MB。其次,调用Configuration conf得到所需要的FileSystem实例。Configuration对象封装了客户端或服务器的配置,通过设置配置文件读取类路径实现core-site.xml。有了FileSystem实例后,调用factory方法FileSystem.getLocal(Configuration conf)。Hadoop文件API使用Path对象编制文件和目录名,使用FileStatus对象存储文件和目录的元数据。IPutMerge程序将调用递归算法合并本地不同目录中的所有文件。使用FileSystem的ListStatus()方法得到本地的目录。FSDataInputStream是Java标准类java.io.DataInputStream的子类,可以提供随机访问的功能,本文用该方法将数据写入HDFS。为实现IPutMerge,创建一个for循环逐一读取inputFiles中的所有文件。部分代码如下所示:
Configuration conf = new Configuration();
......
Path localPath = new Path((“/home/hadoop/Desktop/重庆市/金矿典型矿床成矿要素图”));
Path hdfsPath = new Path((“/opt/hadoop/dfs/data/重庆市/金矿种潜力评价图库/矿产及其预测/金矿典型矿床成矿要素图”));
if(out==null){
out = hdfsFS.create(hdfsPath);
}
readLocalFileWriteToHDFS(localPath, localFS);
......
FileStatus[] inputFiles = localFS.listStatus(localPath);
for(int i =0; i < inputFiles.length; i++){
boolean isDir = inputFiles[i].isDirectory();
if(isDir){
readLocalFileWriteToHDFS(inputFiles[i].getPath(), localFS);
}
if(inputFiles[i].isFile()){
……
}
}
}
最后,调用MapReduce程序,将数据上传到HDFS之上。Shell命令为:
[hadoop@hdmaster1 Desktop] $ hadoop jar HDFSpd.jar数据.HDFSpd2
3. 实验验证
3.1 小文件优化对比实验
为了验证优化后的方案更具优势,本文从2个方面进行对比测试:①实验数据在HDFS上的写入性能;②文件操作过程中HDFS的NameNode内存占用结果。
(1)实验环境
本文实验采用4个节点的Hadoop集群,其中包括1个NameNode和3个DataNode,具体配置如表 2。
表 2 集群配置情况Table 2. Cluster configuration组件 配置 Hadoop版本 Hadoop2.7.2 操作系统 Red Hat Enterprise Linux Server release 6.7(Santiago) Linux内核版本 2.6.32-573.e16.x86_64 JDK 1.7.0_91 网络带宽 100MB NameNode 八核2.4.0GHzCPU, 16G内存,600G硬盘,数量1 DataNode 八核2.4.0GHzCPU, 8G内存,600G硬盘,数量3 (2)写操作性能对比测试
本实验分别选取500, 1000, 10000, 20000, 30000, 40000个大小为1~1000KB的小文件为存储数据,分别进行数据存储,记录它们各自的存储时间,取3次实验结果的平均值,实验结果见图 6。
图 6表明,采用IPutMerge方法优化后的HDFS的写操作明显快于原始HDFS。这是因为,每写入一个文件到HDFS,NameNode都要对其进行创建和分配数据块的操作,而本文优化后的HDFS中,当n个小文件组成的大文件写入时,NameNode仅被调用一次。另外,Client对大文件使用的缓存机制,每128MB数据的请求被发送到NameNode,而不是发送每个小文件。
(3)内存占用对比测试
海量小文件会耗费主节点内存,造成NameNode瓶颈问题,进而严重影响HDFS的性能,为了分析基于HDFS的分布式文件存储系统中的NameNode占用情况并设计实验。
本实验分别选取500, 1000, 10000, 20000, 30000, 40000个大小为1~1000KB的小文件作为实验数据,在半小时内不断写入各文件到HDFS,并观察NameNode所占系统内存变化,取3次实验结果的平均值。内存使用量结果如图 7所示。
图 7显示了2种情况下的内存使用情况,从结果可以看出,在小文件数量小于1000个的情况下,优化效果并不明显,然而随着小文件数量的急剧增长,优化后的NameNode所占内存量远远低于优化前的HDFS中。这是因为,NameNode主要保存文件元数据及文件所在块的元数据。优化前的HDFS进行数据存储时,每个小文件占据了一个Block,则NameNode需占用大量内存来保存这些数据。而优化后的HDFS,NameNode保存了单个组合文件及Block的元数据,因此,系统内存占用量则会大幅度降低。
3.2 Hadoop与Oracle对比实验
本文实验通过对比2种空间数据存储方式:①传统空间数据存储方式,即采用Oracle与MapGis相结合进行空间数据存储。② Hadoop平台,通过HDFS进行数据存储。分析实验结果,验证本文方法更具优势。
(1)实验环境
表 3给出了测试用到的硬件环境,其中Oracle采用单节点,Hadoop则是在4台电脑上部署的集群。
表 3 测试数据库硬件环境Table 3. Test database hardware environment组件 Oracle Hadoop 操作系统 Windows7专业版 Red Hat Enterprise Linux Server release 6.7(Santiago) 服务器数量 1台(单节点) 4台(Hadoop集群) 网络带宽 100MB 100MB CPU性能 四核 八核 CPU主频 2.80GHz 2.40GHz 内存 8GB 8GB (2)数据导入对比实验
本实验以重庆市矿产资源潜力评价数据作为研究对象,选取100, 1000,10000, 50000, 100000个大小为1~1000KB的小文件为存储数据,分别采用Oracle与Hadoop先后进行数据存储,求取3次对比实验结果的平均值(图 8)。
从图 8可以看出,当文件数量较少时,2种存储方式效率持平,改进后的Hadoop存储方式则略占优势;当数据量很少时,较之传统的Hadoop存储,Oracle效率可能更高,这是因为使用Hadoop进行数据存储时,涉及到NameNode的元数据存储及DataNode的选取,耗费时间较长,优化后的Hadoop则仅需要调用少量的NameNode,大大节省了系统开销时间;当数据量较大时,尤其达到10000个以后,Hadoop在地质数据存储方面则显示出了巨大优势,写入数据所需时间大为缩短。而传统的Oracle数据库,数据存储由于主要集中在一台物理存储节点上,随着数据量不断增加大致呈线性增长。
3.3 数据导出对比实验
本实验以重庆市矿产资源潜力评价数据作为研究对象,选取100, 1000,10000, 50000, 100000个大小为1~1000KB的小文件为研究数据,将Oracle与Hadoop中存储的数据分别进行下载,记录它们各自的响应时间,对比3次实验结果,求取其平均值。
对比2种方式,从实验结果(图 9)可以看出,在数据量很小时,使用Hadoop进行数据读取并没有太大优势,比起传统Oracle仅略占优势。这是因为,当数据量少时,Hadoop本身的系统开销需要花费更多的数据处理时间,然而改进后的Hadoop将多个小文件合并为一个大文件,大大减少了访问数据量。因此,比起存储小数据量更占优势的Oracle来说,效率还要稍高。当数据量大幅度上升时,尤其数据量超过10000个时,Oracle的单节点数据输出则较吃力,系统响应时间大致呈线性增长,而Hadoop的多节点并行工作突显出了更大的优势。
4. 结语
大数据时代的到来带动了地质大数据的发展,而地质数据对城市规划、建设、安全等都具有重要的指导意义,如何有效存储地质数据成为了亟待解决的现实问题。本文针对海量地质矿产数据的存储问题,提出了一种全新的数据存储方案,对地质行业的发展具有一定的参考价值。实验表明:
(1)HDFS不适合海量地质小文件的存储,而优化后的HDFS数据存储则具有显著优势;
(2)当数据量很少时,基于Hadoop的存储效率优势并不明显,而当数据量急剧增长时,Hadoop则展示出了海量数据的存储优势;
(3)本文提出的方案是有效的,为地质数据的存储与管理提供了一种可行的技术方案。
致谢: 成文过程中中国地质科学院地质研究所李锦轶、张进教授提出了许多保贵意见,野外工作中得到了李锦轶、胡道功教授的细心指导,特此致谢。 -
![]()
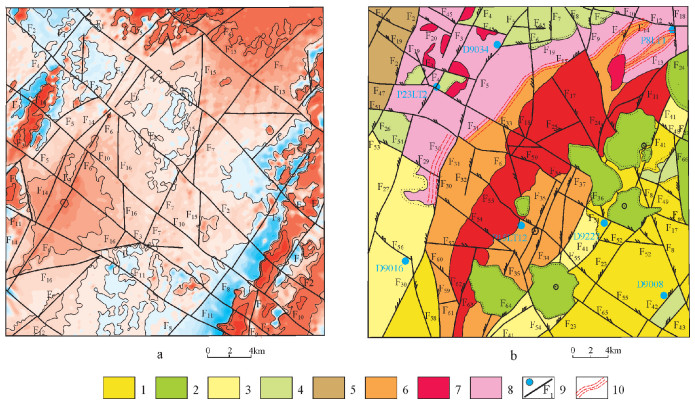
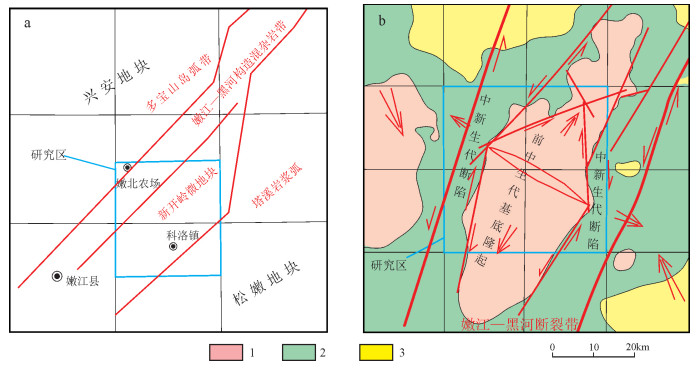
图 1 嫩江科洛一带构造位置图(a)与1: 20万布格重力平面等值线图(b)
Figure 1. Geotectonic location (a) and 1: 200000 Bouguer gravity contour map (b) of Keluo area of Nenjiang County
![]()
图 2 嫩江科洛一带1: 5万航磁等值线图(a)与构造地质图(b)
1—新生代沉积岩;2—新生代玄武岩;3—晚白垩世沉积岩;4—早白垩世中基性火山岩;5—早二叠世中酸性火山岩;6—中元古代结晶基底;7—晚侏罗世深熔花岗岩;8—早石炭世花岗岩;9—断裂及构造验证点;10—韧性剪切带
Figure 2. 1: 50000 aeromagnetic contour map (a) and tectono-geological map (b) of Keluo area of Nenjiang County
![]()
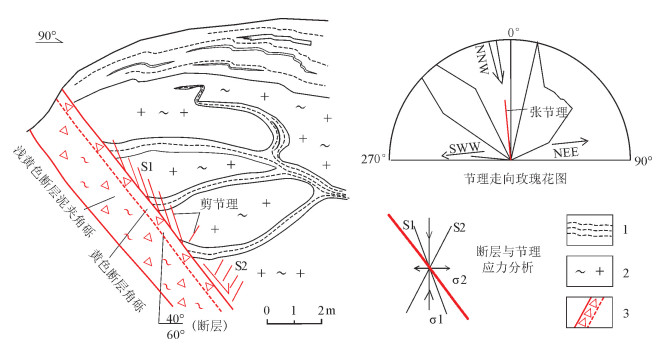
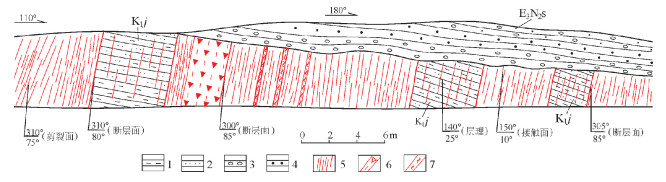
图 3 嫩江县科洛一带发育NW向正断层
1—混合岩基体;2—混合花岗岩;3—断层破碎带
Figure 3. A NW-trending normal fault developed in Keluo area of Nenjiang County
![]()
图 4 科洛南西下白垩统甘河组安山岩中的NW向张性断裂
1—安山岩;2—断层破碎带;3—断层泥;4—密集破裂带
Figure 4. A NW-trending extensional fault developed in the andesite of Lower Cretaceous Ganhe Formation in southwest Keluo area
![]()
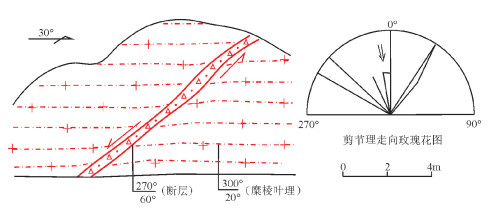
图 5 早白垩世安山岩中NE向逆断层
Figure 5. A set of NE-trending thrust faults developed in Early Cretaceous andesite
![]()
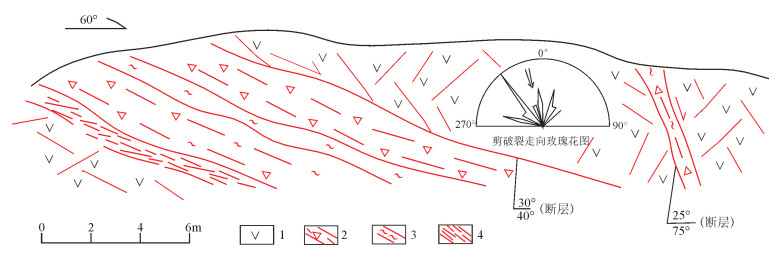
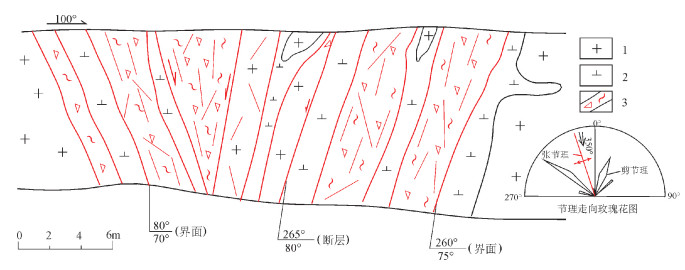
图 6 早白垩世玄武安山岩中NE向走滑断裂
Figure 6. A set of NE-trending strike-slip faults developed in Early Cretaceous basaltic andesite
![]()
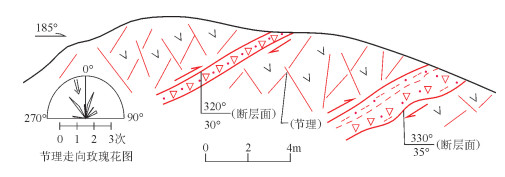
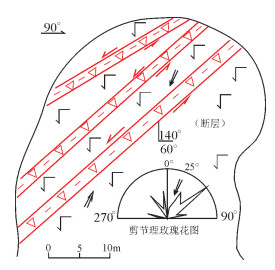
图 7 平顶山东下白垩统九峰山组沉积岩中的NE向压扭性断裂
1—泥岩;2—粉砂岩;3—砾岩;4—砂岩;5—密集破裂带;6—断层破碎带;7—断层泥;8—渐新统-上新统孙吴组;9—下白垩统九峰山组
Figure 7. A set of NE-trending transpressional faults developed in Lower Cretaceous Jiufengshan Formation in east Pingdingshan area
![]()
图 8 早石炭世花岗岩中SN向张性断层
Figure 8. A NS-trending extensional fault developed in Early Cretaceous granite
-
李锦轶, 莫申国, 和政军, 等.大兴安岭北段地壳左行走滑运动的时代及其对中国东北及邻区中生代以来地壳构造演化重建的制约[J].地球前缘, 2004, 11(3):157-168. http://www.cqvip.com/QK/98600X/2004003/10851976.html 王洪波, 杨晓平, 大兴安岭北段新一轮国土资源大调查以来取得的主要基础地质成果与进展[J].地质通报, 2013, 32(2/3):526-532. https://www.wenkuxiazai.com/doc/8793cf0a312b3169a451a49e.html 郭奎城, 王磊, 金哲岩.物化探方法在黑龙江古金厂地区水系沉积物异常查证中的应用[J].世界地质, 2010, 29(2):336-341. http://www.cqvip.com/qk/94166X/201002/34363179.html 孔繁辉, 王天意, 宋晓东, 等.综合方法找矿在内蒙古吉尔敖包多金属矿勘查中的应用[J].地质调查与研究, 2010, 33(2):108 -114. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=qhwjyjjz201002005 王海燕, 焦新华, 吴燕冈.内蒙古阿龙山区域地质填图中的重磁联合人机交互解释[J].物探与化探, 2005, 29(1):16-18. http://industry.wanfangdata.com.cn/yj/Magazine?magazineId=wtyht&yearIssue=2005_1 范正国, 方迎尧, 王懋基, 等.航空物探技术在1: 25万区域地质调查中的应用[J].物探与化探, 2007, 31(6):504-509. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=wtyht200706006 张文斌.高精度航空物探测量在地质填图中的应用[J].物探与化探, 2004, 28(4):283-286. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=wtyht200404001 丸山茂德, 濑野澈三. 沈步晚译. 日本列岛周围的板块相对运动和构造运动[J]. 国外地质, 1997, 3: 1-9. 杨巍然, 杨森楠, 等.造山带结构与演化的现代理论和研究[M].武汉:中国地质大学出版社, 1991. 管志宁.地磁场与磁力勘探[M].北京:地质出版社, 2005. 王富群, 刘国栋.根河高磁资料在划分岩性与断裂构造中的应用分析[J].中州煤炭, 2013, 5:29-31. http://www.cqvip.com/QK/96842X/201305/45973187.html 史俊波, 康孔跃, 张辉善, 等. SPOT5数据在西昆仑麻扎构造混杂岩带填图中的应用[J].国土资源遥感, 2016, 28(1):107-113. doi: 10.6046/gtzyyg.2016.01.16

 下载:
下载:








计量
- 文章访问数: 2949
- HTML全文浏览量: 438
- PDF下载量: 2479
